

Intuition: Tái xây dựng Internet cho kỷ nguyên AI Agent
Cuộc khủng hoảng nợ công nghệ ẩn trong giấc mơ AI
Báo cáo này được thực hiện bởi Tiger Research, phân tích cách tiếp cận của Intuition trong việc tái thiết hạ tầng web cho kỷ nguyên AI agent thông qua cấu trúc tri thức dựa trên Atoms, token-curated registries để đạt được đồng thuận tiêu chuẩn, và hệ thống đo lường độ tin cậy dựa trên signal.
TL;DR
Kỷ nguyên AI agent đã bắt đầu. Nhưng AI agent chưa thể phát huy hết tiềm năng. Hạ tầng web hiện tại được thiết kế cho con người, không phải cho agent. Các website dùng nhiều định dạng dữ liệu khác nhau, thông tin lại thiếu xác thực. Điều này khiến agent khó hiểu và xử lý dữ liệu.
Intuition phát triển tầm nhìn của Semantic Web bằng cách tiếp cận Web3. Nó khắc phục những giới hạn hiện có. Hệ thống tổ chức tri thức thành các Atom. Nó sử dụng Token Curated Registries (TCR) để đạt đồng thuận về cách sử dụng dữ liệu. Signal quyết định mức độ tin cậy của dữ liệu đó.
Intuition sẽ thay đổi Internet. Web hiện tại giống như những con đường đất chưa được trải nhựa. Intuition xây dựng “xa lộ” nơi các agent có thể vận hành an toàn. Nó sẽ trở thành tiêu chuẩn hạ tầng mới, mở ra tiềm năng thật sự của kỷ nguyên AI agent.
1. Kỷ nguyên Agent bắt đầu: Hạ tầng Web đã đủ chưa?
Kỷ nguyên AI agent đang tăng tốc. Ta có thể hình dung một tương lai nơi các agent cá nhân (personal agent) lo liệu mọi thứ, từ lên kế hoạch du lịch đến quản lý tài chính phức tạp. Nhưng thực tế không đơn giản như vậy. Vấn đề không nằm ở khả năng của AI, mà ở chính hạ tầng web hiện tại.
Web được xây dựng cho con người đọc và diễn giải qua trình duyệt. Vì vậy, nó không phù hợp với các agent cần phân tích ngữ nghĩa và kết nối quan hệ giữa nhiều nguồn dữ liệu. Những hạn chế này thể hiện rõ trong dịch vụ hàng ngày. Ví dụ, một website hãng bay có thể ghi giờ khởi hành là “14:30,” trong khi website khách sạn lại ghi giờ check-in là “2:30 PM.” Con người dễ dàng hiểu đó là cùng một thời điểm, nhưng agent sẽ coi đây là hai định dạng dữ liệu hoàn toàn khác nhau.
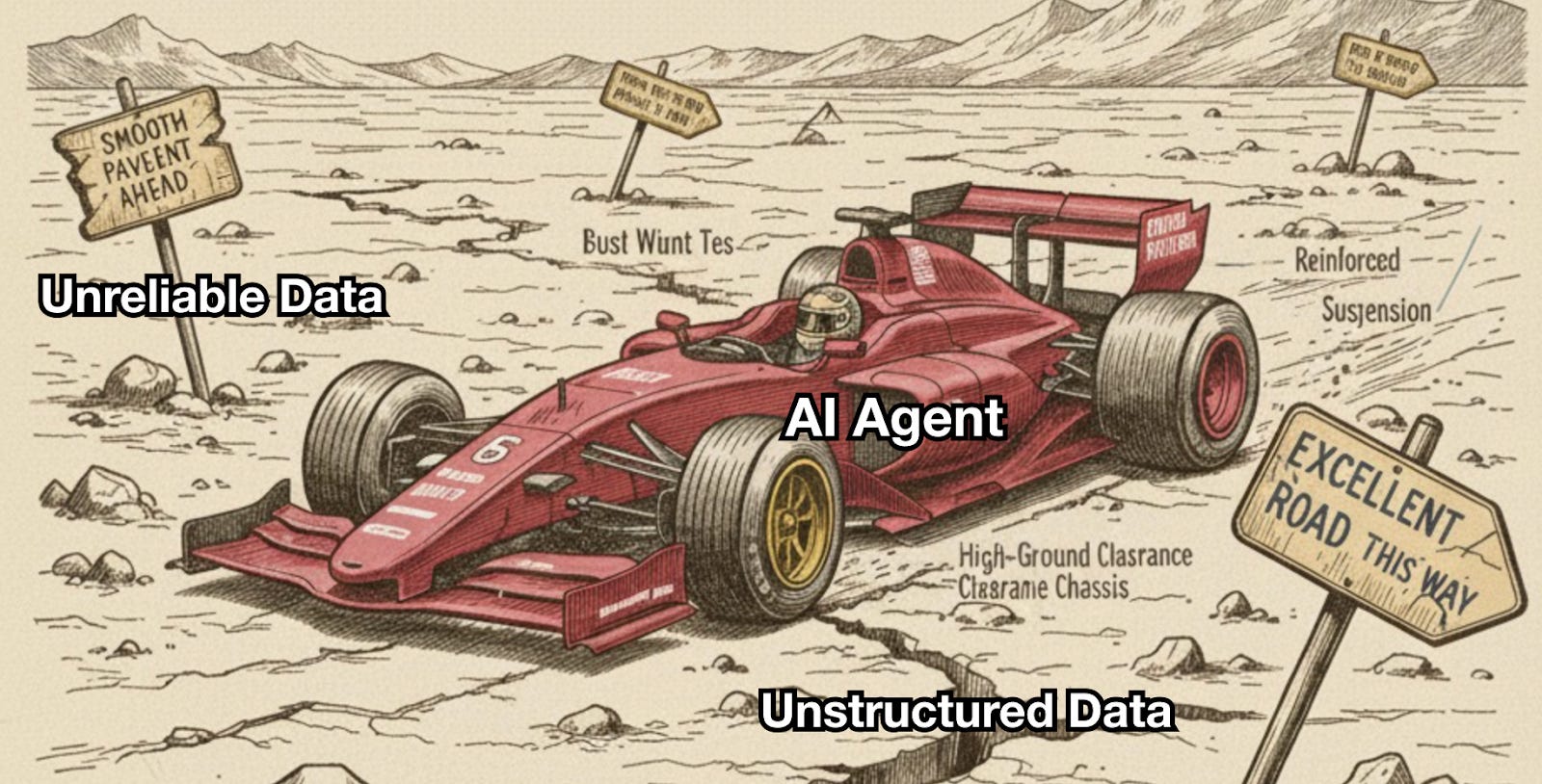
Vấn đề không chỉ dừng ở sự khác biệt định dạng. Thách thức cốt lõi là liệu agent có thể tin tưởng dữ liệu đó hay không. Con người có thể xử lý thông tin thiếu bằng cách dựa vào ngữ cảnh và kinh nghiệm. Agent thì khác, chúng thiếu các tiêu chuẩn rõ ràng để đánh giá nguồn gốc hay độ tin cậy. Điều này khiến chúng dễ bị ảnh hưởng bởi dữ liệu sai lệch, dẫn đến kết luận sai và thậm chí là “ảo giác.”
Cuối cùng, ngay cả những agent tiên tiến nhất cũng khó vận hành hiệu quả trong điều kiện này. Chúng giống như những chiếc xe F1: dù mạnh mẽ đến đâu cũng không thể đạt tốc độ tối đa trên con đường đất đá — tức dữ liệu phi cấu trúc. Và nếu dọc đường xuất hiện những biển báo sai — dữ liệu không đáng tin cậy — chúng có thể chẳng bao giờ về đích.
2. Nợ công nghệ của Web: Xây dựng lại nền tảng
Vấn đề này đã được nêu ra hơn 20 năm trước bởi Tim Berners-Lee, cha đẻ của World Wide Web, thông qua đề xuất về Mạng ngữ nghĩa (Semantic Web).
Ý tưởng cốt lõi của Mạng ngữ nghĩa rất đơn giản: cấu trúc thông tin trên web sao cho máy móc có thể hiểu, chứ không chỉ hiển thị dưới dạng văn bản cho con người đọc. Ví dụ, “Tiger Research được thành lập năm 2021” rõ ràng với con người, nhưng với máy chỉ là một chuỗi ký tự. Mạng ngữ nghĩa sẽ cấu trúc lại thành: “Tiger Research (chủ thể) – thành lập (vị ngữ) – 2021 (tân ngữ)” để máy có thể diễn giải ý nghĩa.
Cách tiếp cận này đi trước thời đại, nhưng cuối cùng lại không thành công. Nguyên nhân chính nằm ở thách thức triển khai. Đạt đồng thuận về định dạng dữ liệu và tiêu chuẩn sử dụng rất khó khăn. Quan trọng hơn, việc xây dựng và duy trì kho dữ liệu khổng lồ dựa trên đóng góp tự nguyện gần như bất khả thi, vì người dùng không nhận được phần thưởng hay lợi ích trực tiếp nào. Thêm vào đó, câu hỏi liệu dữ liệu được tạo ra có đáng tin cậy hay không vẫn chưa có lời giải.
Dù vậy, tầm nhìn của Mạng ngữ nghĩa vẫn còn nguyên giá trị. Nguyên tắc rằng máy móc cần hiểu và khai thác dữ liệu ở mức ngữ nghĩa không hề thay đổi. Trong kỷ nguyên AI, nhu cầu này thậm chí còn trở nên cấp thiết hơn.
3. Intuition: Hồi sinh Mạng ngữ nghĩa theo cách Web3

Intuition phát triển tầm nhìn của Mạng ngữ nghĩa bằng cách tiếp cận Web3 để giải quyết những hạn chế trước đây. Trọng tâm nằm ở việc tạo ra một hệ thống khuyến khích người dùng tham gia tự nguyện vào việc tích lũy và xác minh dữ liệu có cấu trúc, chất lượng. Từ đó xây dựng nên các đồ thị tri thức (knowledge graph) mà máy móc có thể đọc hiểu, có nguồn gốc rõ ràng và có thể xác thực. Đây chính là nền tảng để các AI agent vận hành đáng tin cậy, đưa chúng ta tiến gần hơn đến tương lai mong đợi.
3.1. Atoms: Những khối xây dựng của tri thức
Intuition bắt đầu bằng cách chia toàn bộ tri thức thành những đơn vị nhỏ nhất gọi là Atoms. Atoms đại diện cho các khái niệm như con người, thời gian, tổ chức, hoặc thuộc tính. Mỗi Atom có một định danh duy nhất (sử dụng công nghệ như Decentralized Identifiers – DIDs) và tồn tại độc lập. Mỗi Atom còn lưu lại thông tin về người đóng góp, cho phép xác minh ai đã thêm dữ liệu gì và vào thời điểm nào.
Lý do phải phân tách tri thức thành Atoms rất rõ ràng. Thông tin thường xuất hiện trong các câu phức tạp. Máy móc (như agent) gặp hạn chế khi tự mình phân tích và hiểu những cấu trúc này. Chúng cũng khó xác định phần nào chính xác và phần nào sai.
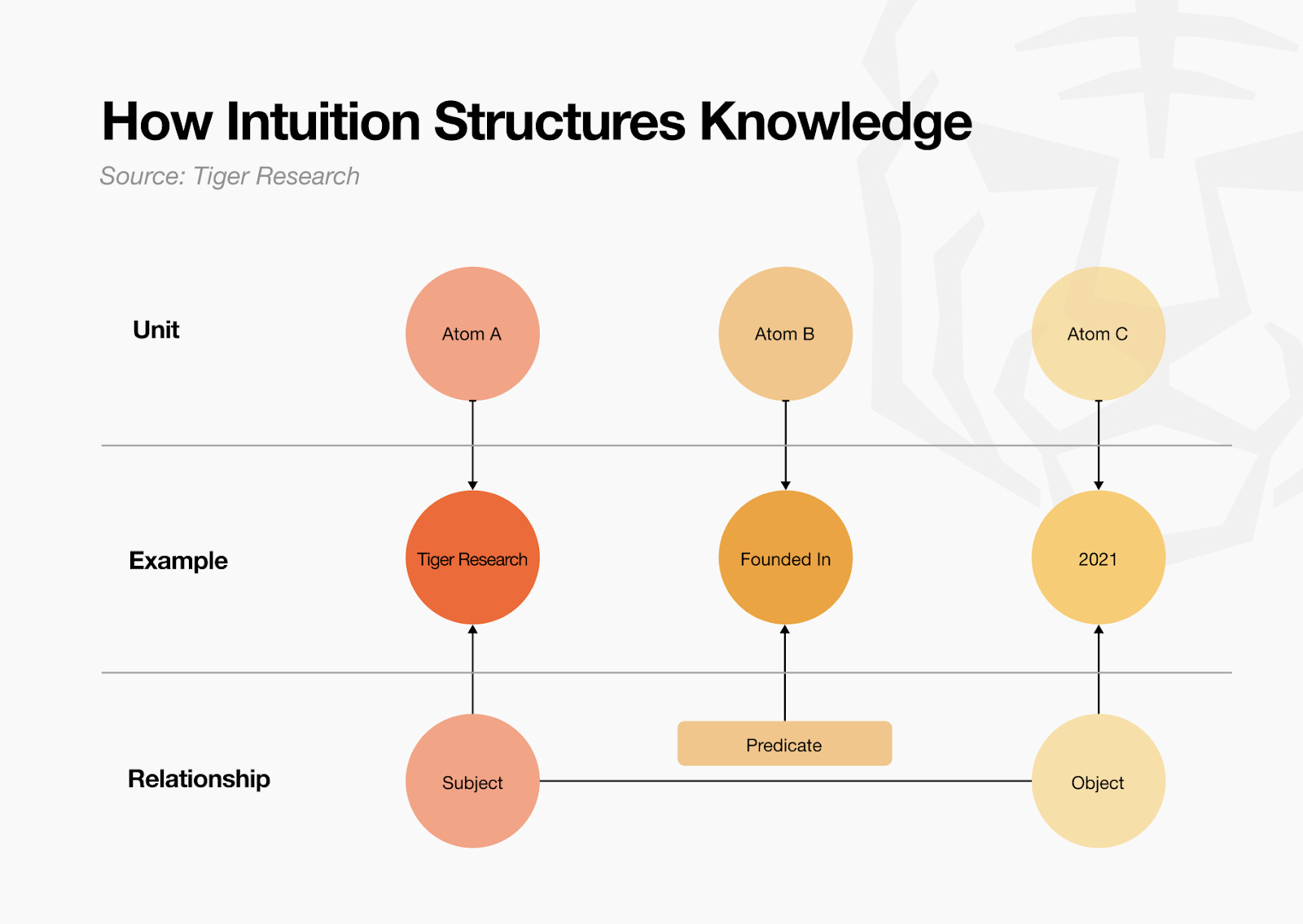
Ví dụ:
Chủ thể (Subject): Tiger Research
Vị ngữ (Predicate): founded in
Đối tượng (Object): 2021
Hãy xét câu “Tiger Research was founded in 2021.” Câu này có thể đúng, hoặc chỉ đúng một phần. Liệu tổ chức này có thật không? “Ngày thành lập” có phải thuộc tính hợp lý không? Và năm 2021 có chính xác không? Tất cả đều cần được xác minh riêng. Nhưng nếu coi cả câu là một đơn vị thì rất khó phân biệt yếu tố nào đúng, yếu tố nào sai, và việc truy vết nguồn gốc từng mảnh thông tin cũng trở nên phức tạp.
Atoms giải quyết vấn đề này. Khi định nghĩa từng thành phần như các Atom độc lập: [Tiger Research], [Founded in], [2021], ta có thể ghi lại nguồn gốc và xác minh từng yếu tố riêng lẻ.
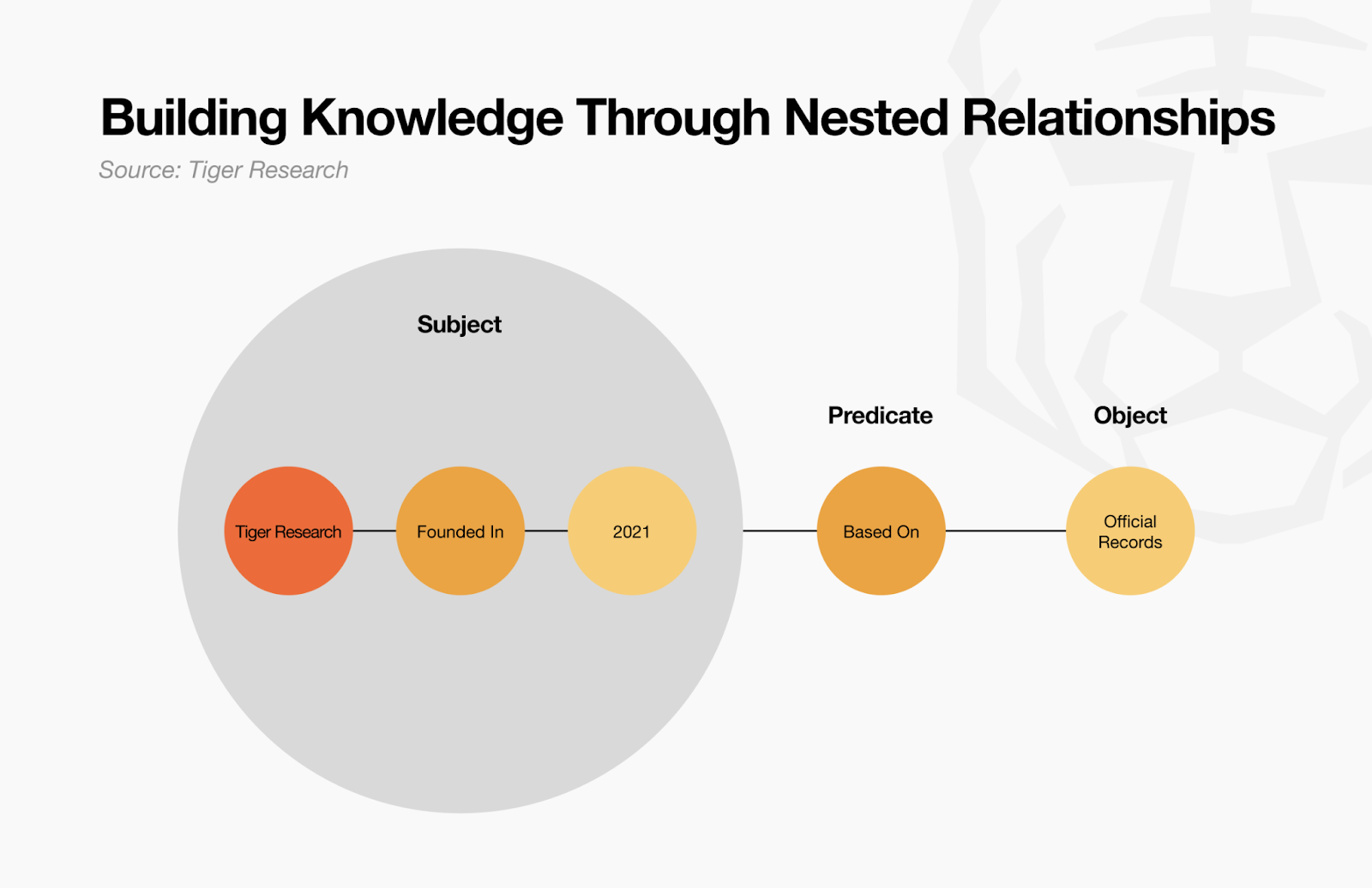
Chủ thể (Subject): Tiger Research's founding date is 2021
Vị ngữ (Predicate): Based On
Giá trị (Object): Official Records
Atoms không chỉ là công cụ phân tách thông tin - chúng hoạt động như những khối Lego có thể ghép lại. Ví dụ, các Atom riêng lẻ [Tiger Research], [Founded In], [2021] khi kết nối sẽ tạo thành một Bộ ba ngữ nghĩa (Triple), mang ý nghĩa: “Tiger Research was founded in 2021.” Cấu trúc này giống với Bộ ba trong RDF (Resource Description Framework) của Mạng ngữ nghĩa.
Các Bộ ba này cũng có thể trở thành Atom mới. Bộ ba “Tiger Research was founded in 2021” có thể mở rộng thành một Bộ ba khác: “Tiger Research’s founding date of 2021 is based on business records.” Bằng cách này, các Atoms và Bộ ba liên tục kết hợp, phát triển từ các đơn vị nhỏ thành cấu trúc lớn hơn.
Kết quả là Intuition xây dựng nên các đồ thị tri thức phân mảnh có thể mở rộng vô hạn từ những phần tử cơ bản. Ngay cả tri thức phức tạp cũng có thể được tách nhỏ để xác minh rồi tái cấu trúc lại.
3.2. Token Curated Registries: Đồng thuận dựa trên thị trường
Nếu Intuition cung cấp khung khái niệm để cấu trúc tri thức thông qua Atoms, thì ba câu hỏi quan trọng tiếp theo là: Ai sẽ đóng góp tạo ra các Atom? Những Atom nào đáng tin cậy? Và khi nhiều Atom cạnh tranh để biểu diễn cùng một khái niệm, cái nào sẽ trở thành tiêu chuẩn?
Intuition giải quyết vấn đề này thông qua Token Curated Registries (TCRs). TCRs lọc dữ liệu dựa trên những gì cộng đồng coi trọng, và cơ chế token staking phản ánh các đánh giá đó. Người dùng sẽ stake token $TRUST, token gốc của Intuition, khi đề xuất các Atom, Bộ ba (Triples) hoặc cấu trúc dữ liệu mới. Những người khác có thể stake ủng hộ nếu thấy đề xuất hữu ích, hoặc phản đối nếu không. Họ cũng có thể stake vào lựa chọn thay thế cạnh tranh. Người dùng nhận phần thưởng nếu dữ liệu họ chọn được sử dụng thường xuyên hoặc đánh giá cao, và mất một phần stake nếu ngược lại.
TCRs không chỉ xác minh từng đóng góp riêng lẻ, mà còn giải quyết hiệu quả bài toán tiêu chuẩn hóa ngữ nghĩa (ontology standardization). Đây là việc quyết định cách biểu diễn nào trở thành tiêu chuẩn chung khi có nhiều lựa chọn cùng tồn tại. Với các hệ thống phi tập trung, thách thức lớn là làm sao đạt được đồng thuận mà không cần điều phối tập trung.
Ví dụ, với hai vị ngữ cạnh tranh cho đánh giá sản phẩm: [hasReview] và [customerFeedback]. Nếu [hasReview] được giới thiệu trước và nhiều người dùng xây dựng dựa trên nó, những người tham gia sớm sẽ nắm giữ lợi ích kinh tế từ sự thành công này. Trong khi đó, những người ủng hộ [customerFeedback] sẽ dần có động lực kinh tế để chuyển sang chuẩn được chấp nhận rộng rãi hơn.
Cơ chế này phản chiếu cách chuẩn ERC-20 được chấp nhận tự nhiên. Các nhà phát triển chọn ERC-20 vì lợi ích tương thích rõ ràng: dễ dàng tích hợp với ví, sàn giao dịch và dApp hiện có. Những lợi ích này thu hút nhà phát triển chọn ERC-20, chứng minh rằng động lực thị trường tự thân có thể giải quyết vấn đề chuẩn hóa trong môi trường phân tán. TCRs vận hành dựa trên nguyên tắc tương tự, giúp giảm tình trạng dữ liệu phân mảnh và tạo môi trường nơi thông tin được hiểu và xử lý nhất quán hơn.
3.3. Signal: Xây dựng mạng lưới tri thức dựa trên niềm tin
Intuition cấu trúc tri thức thông qua Atoms và Bộ ba, đồng thời dùng cơ chế khuyến khích để đạt đồng thuận về “dữ liệu nào thực sự được sử dụng.”
Một thách thức cuối cùng vẫn còn: chúng ta có thể tin tưởng thông tin đó đến mức nào? Intuition giới thiệu Signal để lấp khoảng trống này. Signal thể hiện mức độ tin tưởng hoặc hoài nghi của người dùng với các Atom hay Bộ ba. Nó không chỉ ghi nhận rằng dữ liệu tồn tại, mà còn phản ánh mức độ ủng hộ dữ liệu đó trong nhiều bối cảnh. Signal hệ thống hóa quá trình xác minh xã hội giống ngoài đời thực, khi ta đánh giá thông tin dựa trên “người đáng tin giới thiệu” hoặc “chuyên gia xác nhận.”
Signal được tích lũy theo ba cách:
Tín hiệu rõ ràng (explicit): đánh giá có chủ đích của người dùng, như việc stake token.
Tín hiệu ẩn (implicit): hình thành từ hành vi sử dụng, ví dụ dữ liệu được truy vấn lặp lại nhiều lần.
Tín hiệu lan truyền (transitive): tạo hiệu ứng quan hệ — khi một người mà tôi tin tưởng xác nhận thông tin, tôi cũng có xu hướng tin tưởng hơn.
Ba dạng này kết hợp để tạo thành một mạng lưới tri thức dựa trên niềm tin, cho thấy ai tin vào điều gì, mức độ ra sao, và trong hoàn cảnh nào.
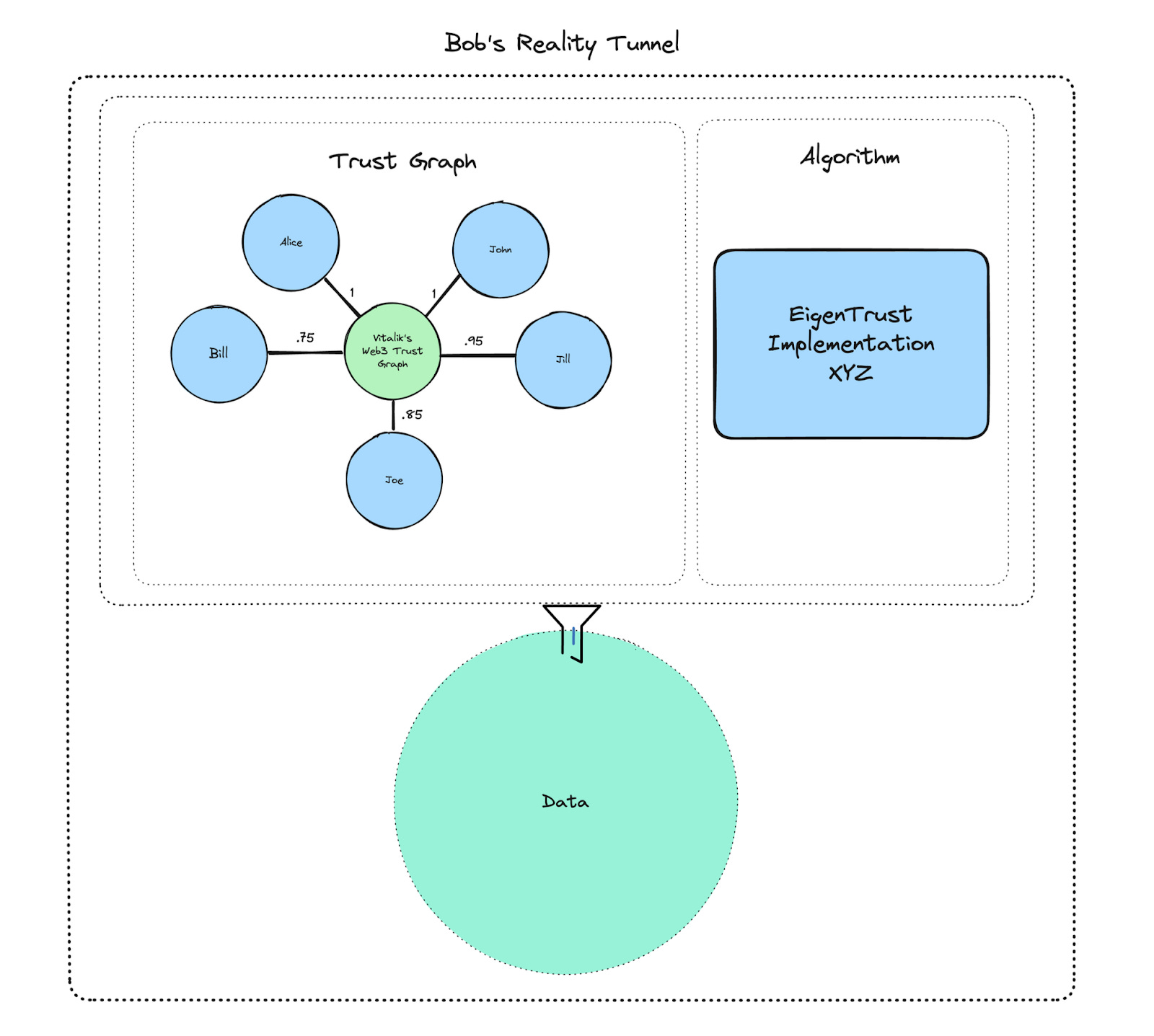
Intuition triển khai điều này thông qua Reality Tunnels. Reality Tunnels cho phép người dùng có góc nhìn cá nhân hóa khi tiếp cận dữ liệu. Người dùng có thể thiết lập “tunnel” để ưu tiên đánh giá của chuyên gia, giá trị từ bạn bè thân cận, hoặc tri thức cộng đồng nhất định. Họ có thể chọn tunnel tin cậy hoặc so sánh nhiều tunnel cùng lúc. Các agent cũng có thể sử dụng tunnel chuyên biệt cho từng mục đích, ví dụ chọn tunnel phản ánh mạng lưới tin cậy của Vitalik Buterin để ra quyết định theo “góc nhìn của Vitalik.”
Mọi tín hiệu đều được ghi nhận on-chain. Người dùng có thể kiểm chứng minh bạch vì sao một thông tin nào đó đáng tin: địa chỉ nào là nguồn gốc, ai xác nhận, bao nhiêu token đã được stake. Quá trình hình thành niềm tin minh bạch này giúp người dùng trực tiếp đối chiếu bằng chứng thay vì chấp nhận mù quáng. Các agent cũng có thể dựa trên nền tảng này để đưa ra quyết định phù hợp với từng bối cảnh và quan điểm cá nhân.
4. Điều gì xảy ra nếu Intuition trở thành hạ tầng Web tiếp theo?
Hạ tầng của Intuition không chỉ là ý tưởng khái niệm, mà là một giải pháp thực tế cho những vấn đề mà các agent đang gặp phải trong môi trường web hiện nay.
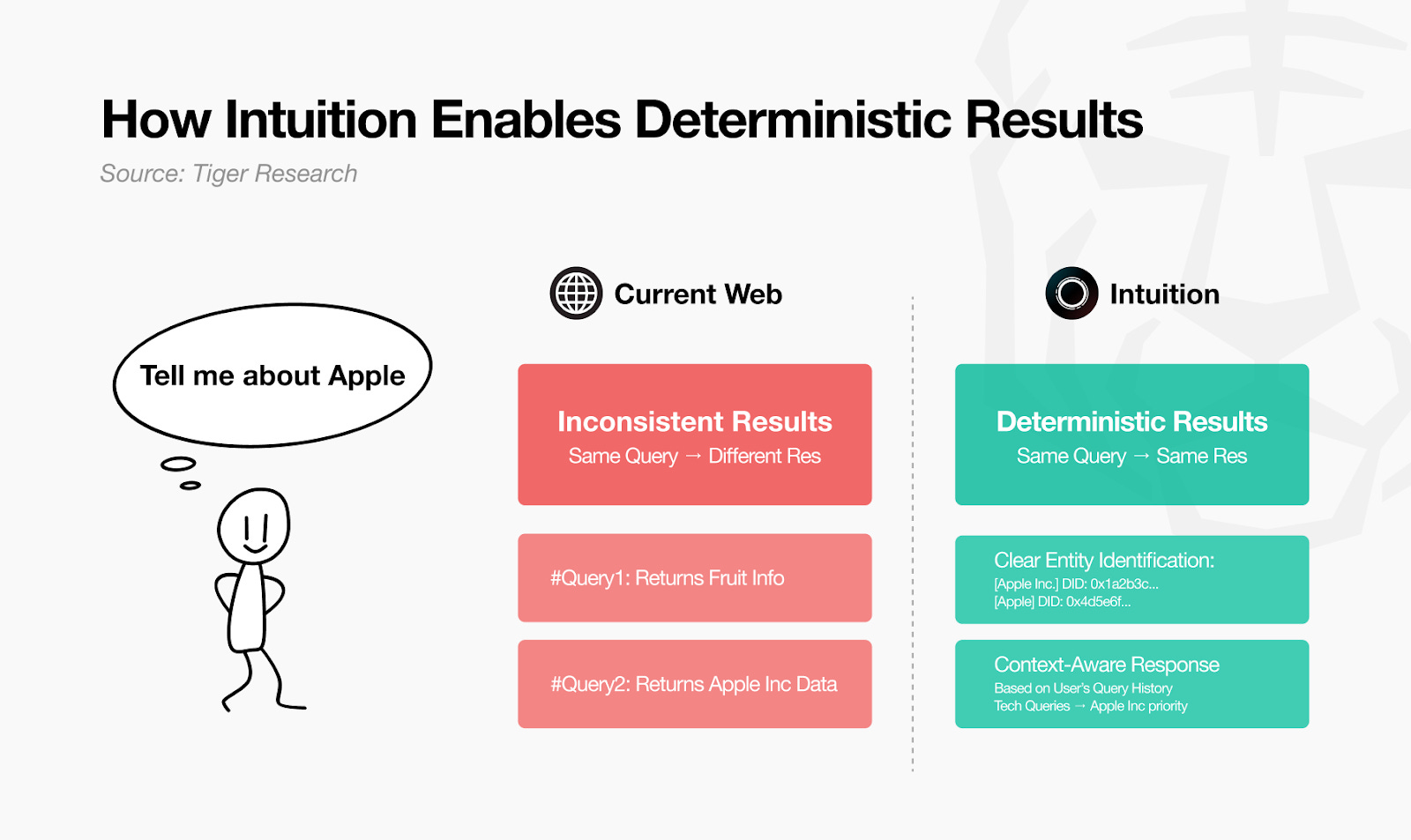
Web hiện tại chứa đầy dữ liệu phân mảnh và thông tin chưa được xác thực. Intuition biến dữ liệu thành đồ thị tri thức có tính xác định, mang lại kết quả rõ ràng và nhất quán cho mọi truy vấn. Các cơ chế xác minh dựa trên token và quy trình tuyển chọn dữ liệu đảm bảo tính chính xác. Nhờ vậy, agent có thể đưa ra quyết định minh bạch mà không phải “đoán mò,” đồng thời nâng cao độ chính xác, tốc độ và hiệu quả.
Intuition còn đặt nền móng cho sự hợp tác giữa các agent. Các cấu trúc dữ liệu chuẩn hóa giúp các agent khác nhau hiểu và trao đổi thông tin theo cùng một cách. Giống như chuẩn ERC-20 đã tạo ra khả năng tương thích của token, đồ thị tri thức của Intuition tạo môi trường nơi các agent có thể phối hợp dựa trên dữ liệu đồng nhất.
Không dừng lại ở hạ tầng dành riêng cho agent, Intuition hướng tới trở thành một lớp nền tảng chung cho toàn bộ dịch vụ số. Nó có thể thay thế các hệ thống niềm tin mà từng nền tảng đang tự xây dựng riêng biệt — từ đánh giá sản phẩm trên Amazon, điểm xếp hạng của Uber, cho tới khuyến nghị trên LinkedIn — bằng một nền tảng thống nhất. Tương tự như HTTP cung cấp chuẩn giao tiếp chung cho web, Intuition đưa ra giao thức chuẩn cho cấu trúc dữ liệu và xác minh độ tin cậy.
Điểm thay đổi quan trọng nhất chính là khả năng di động dữ liệu. Người dùng trực tiếp sở hữu dữ liệu mình tạo ra và có thể mang đi bất cứ đâu. Dữ liệu không còn bị “giam” trong từng nền tảng riêng lẻ, mà được kết nối, tái cấu trúc và định hình lại toàn bộ hệ sinh thái số.
5. Tái thiết nền tảng cho kỷ nguyên agent sắp tới
Mục tiêu của Intuition không chỉ là cải tiến kỹ thuật đơn thuần. Nó hướng đến việc vượt qua “khoản nợ công nghệ” tích lũy suốt 20 năm qua và tái thiết hạ tầng web từ gốc. Khi Mạng ngữ nghĩa được đề xuất lần đầu, tầm nhìn rất rõ ràng, nhưng thiếu động lực khuyến khích sự tham gia. Ngay cả khi viễn cảnh đó thành hiện thực, lợi ích mang lại vẫn chưa rõ ràng.
Giờ đây tình hình đã thay đổi. Sự tiến bộ của AI đang biến kỷ nguyên agent thành hiện thực. Các AI agent không còn chỉ là công cụ đơn giản. Chúng có thể thực hiện các nhiệm vụ phức tạp thay con người, tự đưa ra quyết định, và hợp tác với nhau. Để làm được điều đó, chúng cần những đổi mới căn bản trong hạ tầng web.
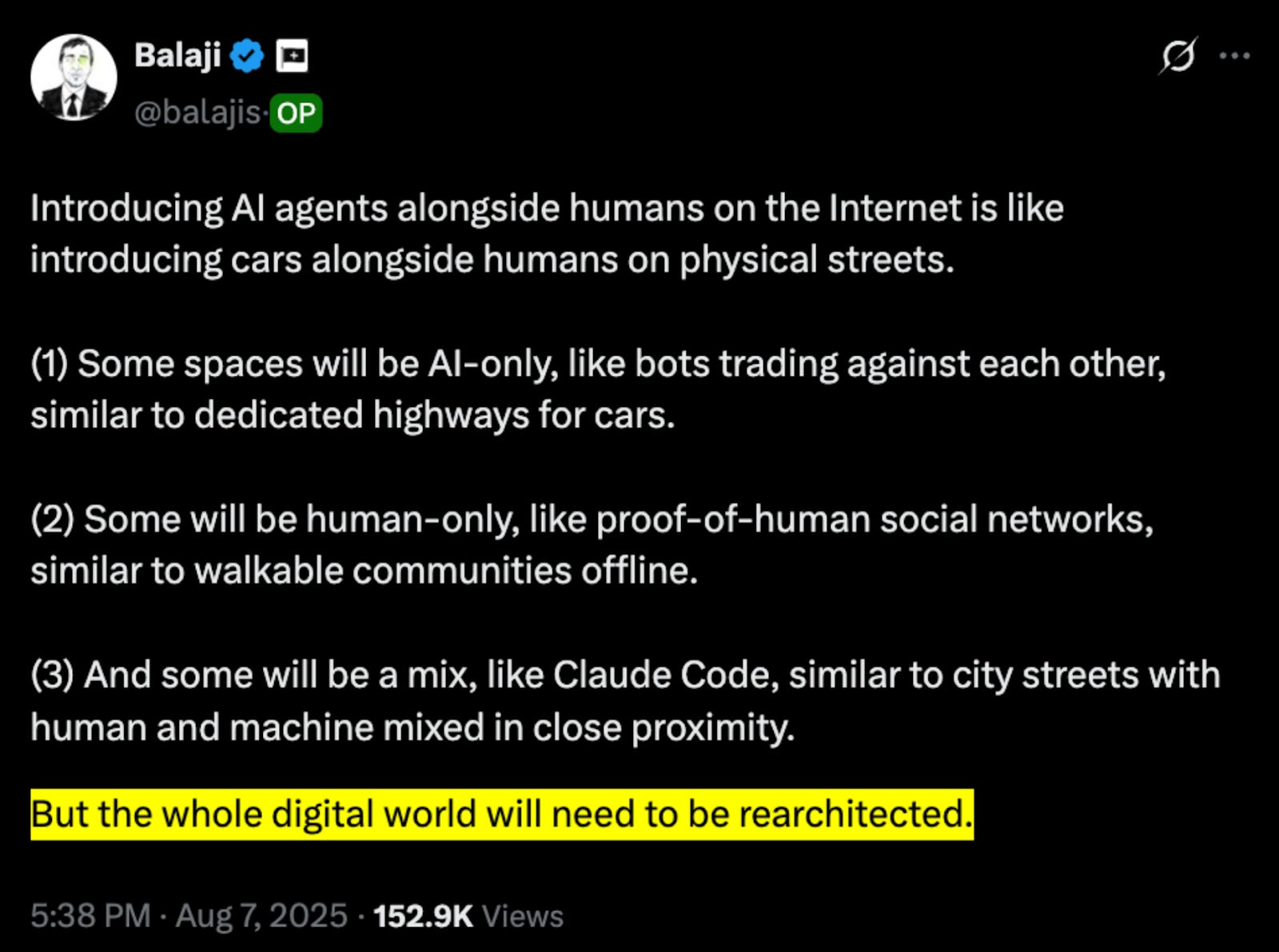
Như Balaji, cựu CTO của Coinbase, đã chỉ ra: chúng ta cần xây dựng hạ tầng phù hợp để các agent có thể vận hành. Web hiện tại giống như những con đường đất đá, chứ chưa phải xa lộ nơi agent di chuyển an toàn trên dữ liệu đáng tin cậy. Mỗi website lại có cấu trúc và định dạng khác nhau. Thông tin thì thiếu ổn định, dữ liệu phi cấu trúc khiến agent khó hiểu. Đây chính là rào cản lớn khiến agent không thể làm việc chính xác và hiệu quả.
Intuition tìm cách tái thiết web để đáp ứng nhu cầu này. Nó hướng tới xây dựng các cấu trúc dữ liệu chuẩn hóa mà agent dễ dàng hiểu và sử dụng. Nó muốn có hệ thống xác minh thông tin đáng tin cậy. Nó cần giao thức cho phép các agent tương tác mượt mà. Điều này giống như cách HTTP và HTML từng tạo ra chuẩn mực cho những ngày đầu Internet. Đây là nỗ lực nhằm thiết lập chuẩn mới cho kỷ nguyên agent.
Tất nhiên, thách thức vẫn còn. Hệ thống không thể hoạt động đúng nếu thiếu sự tham gia và hiệu ứng mạng đủ lớn. Để đạt tới “khối lượng tới hạn” cần rất nhiều thời gian và nỗ lực. Vượt qua quán tính của hệ sinh thái web hiện tại là điều không hề dễ. Việc thiết lập chuẩn mới luôn khó khăn. Nhưng đây là một bài toán buộc phải giải. Bước “tái nền” mà Intuition đề xuất chính là chìa khóa để vượt qua những trở ngại này, mở ra tiềm năng mới cho kỷ nguyên agent — vốn mới chỉ đang ở giai đoạn bắt đầu hình dung.
🐯 More from Tiger Research
Read more reports related to this research.Tuyên Bố Miễn Trách Nhiệm
Báo cáo này được tài trợ một phần bởi Intuition. Tuy nhiên, chúng tôi không bảo đảm rõ ràng hay ngụ ý về tính chính xác, đầy đủ hoặc sự phù hợp của thông tin. Chúng tôi từ chối mọi trách nhiệm đối với bất kỳ tổn thất nào phát sinh từ việc sử dụng báo cáo này hoặc nội dung của nó. Các kết luận và khuyến nghị trong báo cáo được đưa ra dựa trên thông tin có sẵn tại thời điểm soạn thảo và có thể thay đổi mà không cần thông báo trước. Tất cả các dự án, ước tính, dự báo, mục tiêu, quan điểm và ý kiến được nêu trong báo cáo này có thể thay đổi mà không cần thông báo và có thể khác hoặc trái ngược với quan điểm của người khác hoặc tổ chức khác.
Tài liệu này chỉ nhằm mục đích cung cấp thông tin và không nên được coi là lời khuyên pháp lý, kinh doanh, đầu tư hoặc thuế. Mọi tham chiếu đến chứng khoán hoặc tài sản số chỉ nhằm mục đích minh họa và không cấu thành khuyến nghị đầu tư hoặc đề nghị cung cấp dịch vụ tư vấn đầu tư. Tài liệu này không nhằm hướng tới nhà đầu tư hoặc các đối tượng tiềm năng đầu tư.
Điều Khoản Sử Dụng
Tiger Research cho phép sử dụng hợp lý các báo cáo của mình. "Sử dụng hợp lý" là nguyên tắc cho phép sử dụng một phần nội dung vì lợi ích công cộng, miễn là không gây tổn hại đến giá trị thương mại của tài liệu. Nếu việc sử dụng phù hợp với mục đích của sử dụng hợp lý, các báo cáo có thể được sử dụng mà không cần xin phép trước. Tuy nhiên, khi trích dẫn báo cáo của Tiger Research, cần tuân thủ các yêu cầu sau 1) Rõ ràng ghi nguồn là "Tiger Research" 2) Đính kèm logo của Tiger Research (đen/trắng). Nếu tài liệu được chỉnh sửa và xuất bản lại, cần có thỏa thuận riêng. Việc sử dụng trái phép các báo cáo có thể dẫn đến hành động pháp lý.
