

Most people use AI daily without thinking about where their data goes. Nesa asks what happens when you stop ignoring that question.
Key Takeaways
AI is already part of daily life, but users overlook how their data passes through central servers
Even CISA’s acting director unknowingly exposed classified documents to ChatGPT
Nesa restructures this by transforming data before transmission (EE) and splitting it across nodes (HSS-EE) so no single party ever sees the original
Academic validation (COLM 2025) and live enterprise deployment (P&G) give Nesa a head start
Whether the broader market adopts decentralized privacy AI over familiar centralized APIs remains the key question
1. Is Your Data Safe?

In January 2026, Madhu Gottumukkala, Acting Director of CISA, the lead U.S. cybersecurity agency, uploaded sensitive government documents to ChatGPT simply to summarize and organize contract-related files.
The breach was not detected by ChatGPT or reported to the government by OpenAI. It was flagged by the agency’s own internal security systems, leading to an investigation for violating security protocols.
Even America’s top cybersecurity official was using AI routinely, to the point of uploading classified material.
We know. Most AI services store user input on central servers in encrypted form. But this encryption is reversible by design. Data can be decrypted and disclosed under valid warrants or emergency circumstances, and users have no visibility into what happens behind the scenes.
2. Privacy AI for Everyday Use: Nesa
AI is already part of daily life. It summarizes articles, writes code, and drafts emails. The real concern is that, as shown in the previous case, even classified documents and personal data are being handed to AI with little awareness of the risk.
The core problem is that all of this data passes through the service provider’s central servers. Even when encrypted, the decryption keys are held by the provider. How can users trust that arrangement?
User input data can be exposed to third parties through multiple channels: model training, safety reviews, and legal requests. On enterprise plans, organization admins can access chat logs. On personal plans, data can still be turned over under a valid warrant.

Now that AI is deeply embedded in everyday life, it is time to ask serious questions about privacy.
Nesa is a project designed to change this structure entirely. It builds a decentralized infrastructure that enables AI inference without entrusting data to a central server. User input is processed in an encrypted state, and no single node can view the original data.
3. How Nesa Solves This
Imagine a hospital using Nesa. A doctor wants an AI to analyze a patient’s MRI for tumors. With current AI services, the image is sent directly to OpenAI or Google servers.
With Nesa, the image is mathematically transformed before it ever leaves the doctor’s computer.
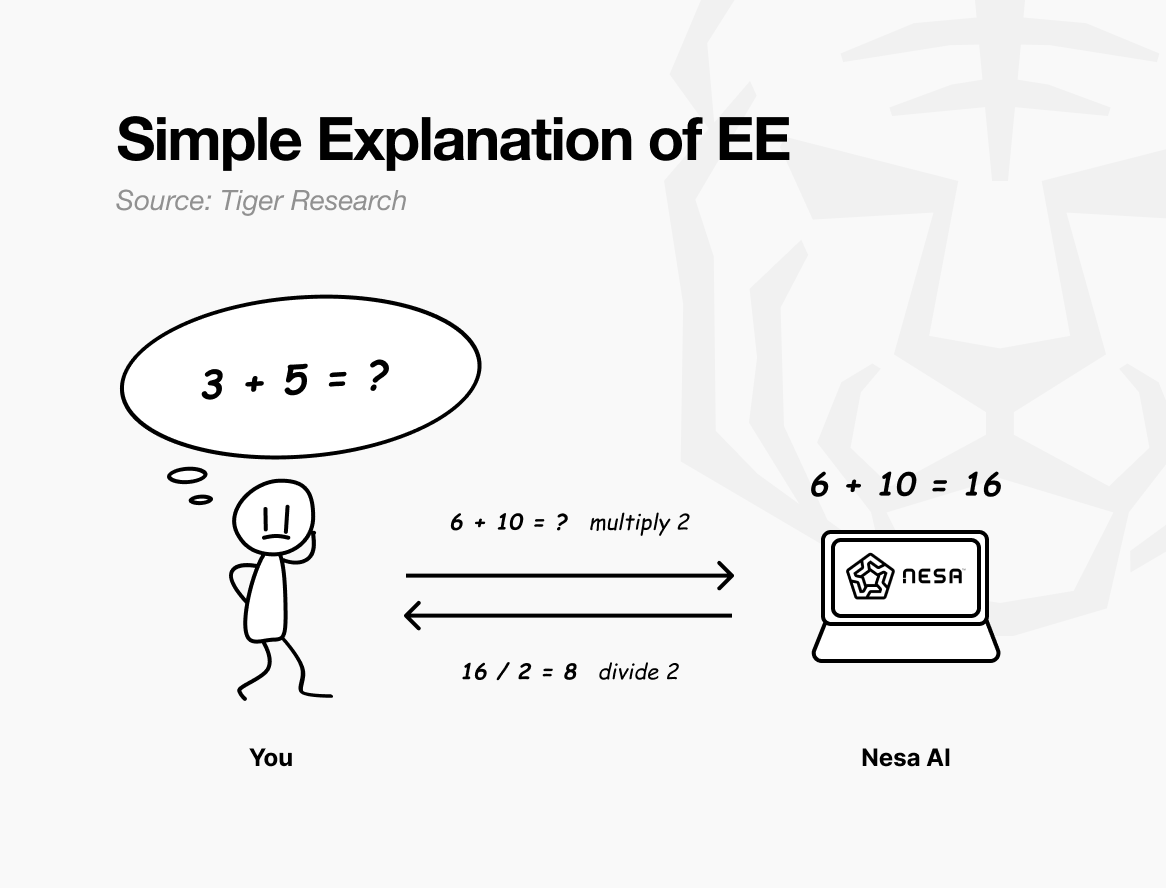
A simple analogy: suppose the original problem is “3 + 5 = ?” If you send it as is, the recipient knows exactly what you are calculating.
But if you multiply every number by 2 before sending, the recipient sees “6 + 10 = ?” and returns 16. You divide by 2 and get 8, the same answer as solving the original. The recipient performed the computation but never learned your original numbers were 3 and 5.
This is exactly what Nesa’s Equivariant Encryption (EE) does. Data is mathematically transformed before transmission. The AI model computes on the transformed data.
The user applies the inverse transformation and gets the same result as if the original data had been used. In mathematics, this property is called equivariance: whether you transform first or compute first, the final result is identical.
In practice, the transformation is far more complex than simple multiplication. It is tailored to the internal computation structure of the AI model. Because the transformation aligns with the model’s processing flow, accuracy is not compromised.
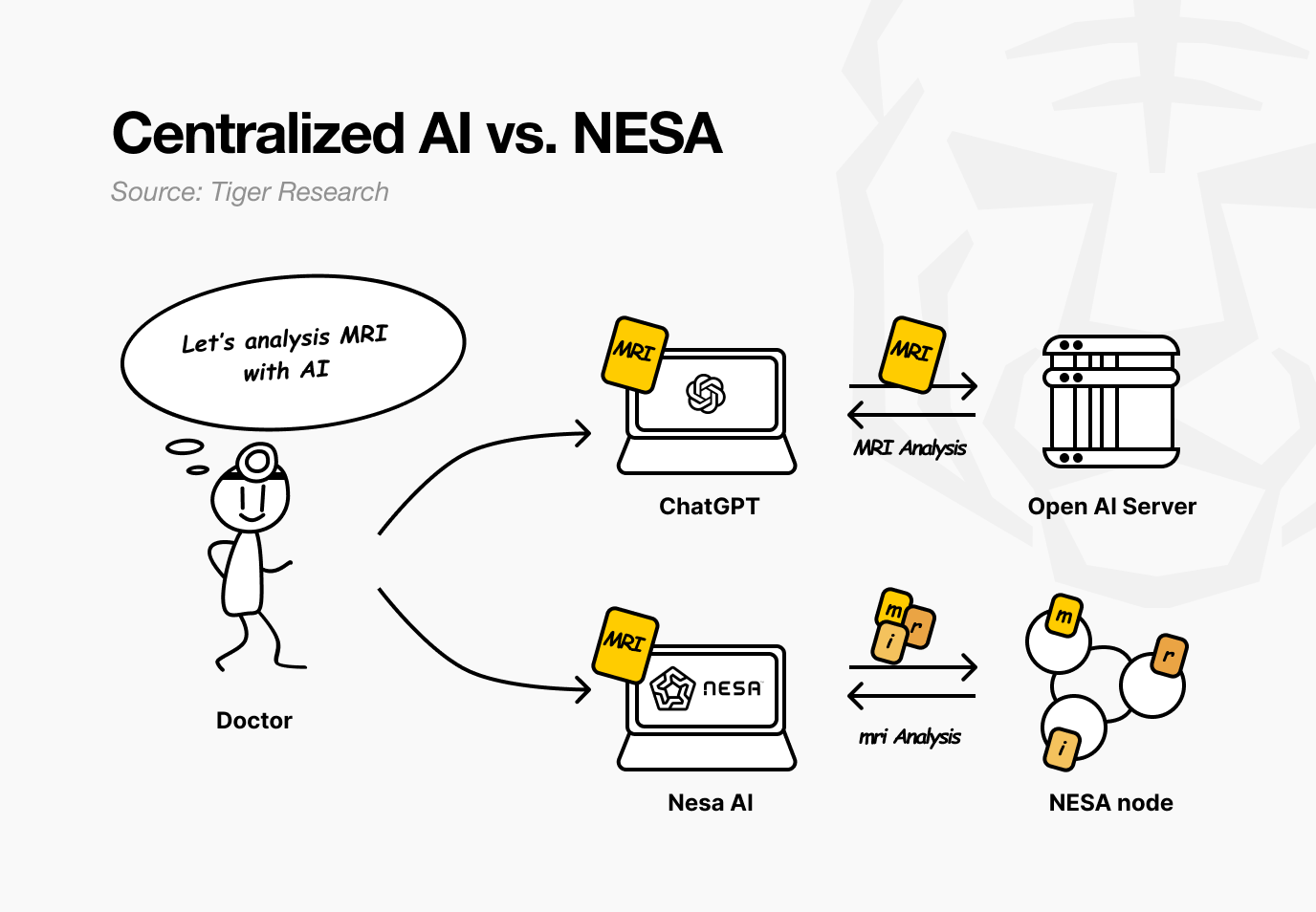
Back at the hospital, the doctor notices no difference. The workflow of uploading an image and receiving a result stays the same. What changes is that no node in between can see the patient’s original MRI.
Nesa goes one step further. EE alone prevents any node from viewing the original data, but the transformed data still exists in full on a single server.
HSS-EE (Homomorphic Secret Sharing over Encrypted Embeddings) splits even the transformed data.
Return to the analogy. EE was applying a multiplication rule before sending the exam sheet. HSS-EE tears that transformed sheet in half, sending the first part to Node A and the second part to Node B.
Each node solves only its own fragment. Neither can see the full problem. Only when both partial answers are combined does a complete result emerge, and only the original sender can perform that recombination.
In summary, EE transforms data so the original cannot be seen. HSS-EE splits even the transformed data so it never exists in one place. Privacy protection is layered twice.
4. Does Privacy Mean Slower Performance?
Stronger privacy means slower performance. This has been a long-standing rule in cryptography. Fully Homomorphic Encryption (FHE), the most widely known approach, is 10,000 to 1,000,000 times slower than standard computation. It is unusable for real-time AI services.
Nesa‘s Equivariant Encryption (EE) works differently. Returning to the math analogy, the cost of applying x2 before sending and ÷ 2 after receiving is minimal.
Unlike FHE, which converts the entire problem into a fundamentally different mathematical system, EE adds only a lightweight transformation on top of existing computations.
Performance benchmarks:
EE: less than 9% latency increase on LLaMA-8B, with accuracy matching the original at over 99.99%.
HSS-EE: 700 to 850 milliseconds per inference on LLaMA-2 7B.
On top of this, MetaInf, a meta-learning scheduler, optimizes efficiency across the network. It evaluates model size, GPU specifications, and input characteristics to automatically select the fastest inference method.
MetaInf achieved 89.8% selection accuracy and a 1.55x speedup over conventional ML-based selectors. It was published at the COLM 2025 main conference, providing academic validation.
The figures above are from controlled test environments. However, Nesa’s inference infrastructure is already deployed in real enterprise settings, confirming production-level performance.
5. Who Uses It and How
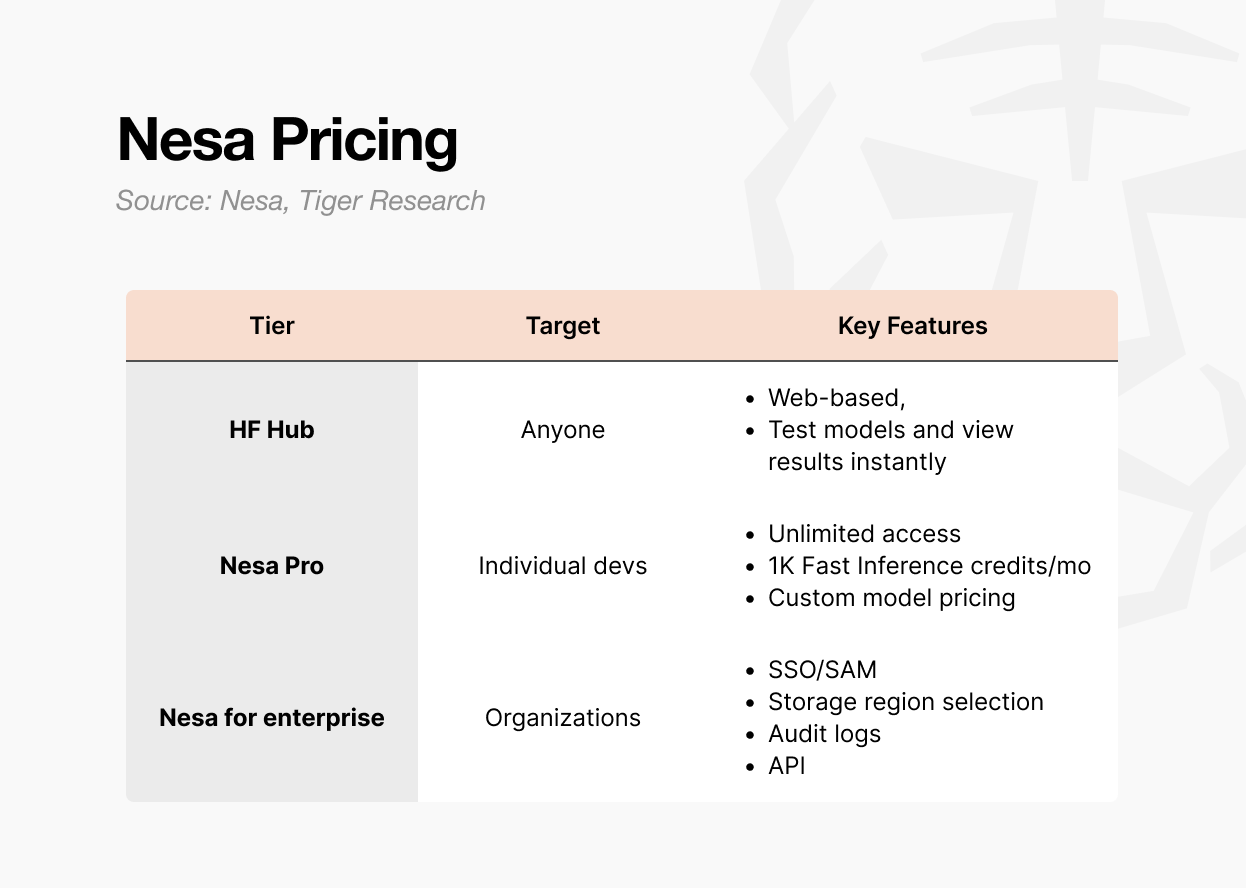
There are three ways to access Nesa.
First is the Playground. Users can select and test models directly on the web. No developer background is required. It allows hands-on experience with inputting data and viewing results per model.
It is the fastest path to see how decentralized AI inference actually works.
Second is the Pro subscription. At $8 per month, it includes unlimited access, 1,000 Fast Inference credits per month, custom model pricing controls, and featured page visibility for models.
This tier is designed for individual developers or small teams looking to deploy and monetize their own models.
Third is Enterprise. This is not a public pricing plan but a custom contract structure. It includes SSO/SAML support, selectable data storage regions, audit logs, granular access controls, and annual-commitment billing.
Pricing starts at $20 per user per month, but actual terms are negotiated based on scale. It is built for organizations integrating Nesa into internal AI pipelines, with API access and organization-level management provided through a separate agreement.
In short: Playground for exploration, Pro for individual or small-team development, Enterprise for organizational deployment.
6. Why a Token Is Needed
A decentralized network has no central administrator. The entities running servers and verifying results are distributed around the world. This raises a natural question: why would anyone keep their GPU running to process someone else’s AI inference?
The answer is economic incentive. In the Nesa network, that incentive is the $NES token.
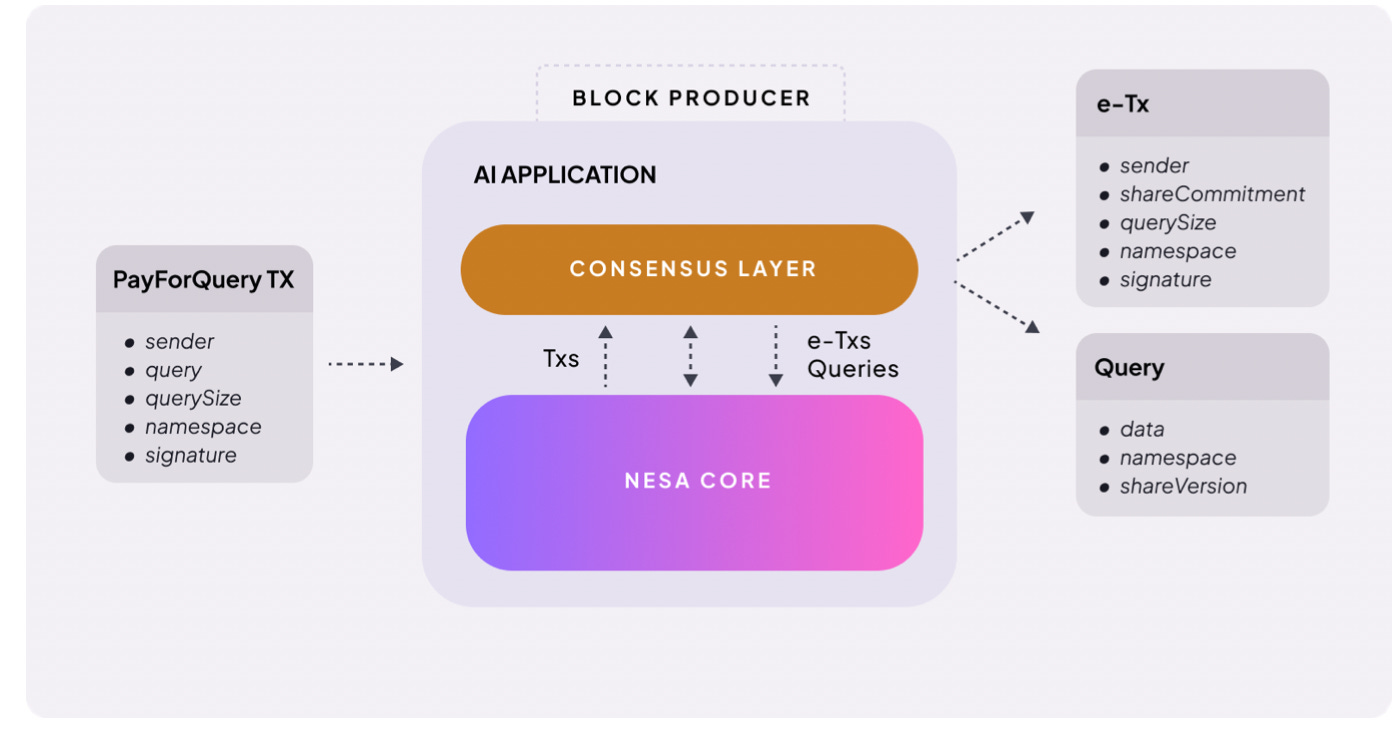
The structure is straightforward. When a user requests AI inference, a fee is attached. Nesa calls this PayForQuery. It consists of a fixed fee per transaction plus a variable fee proportional to data size.
Higher fees receive priority processing, the same principle as gas fees on a blockchain.
The recipients of these fees are miners. To participate in the network, miners must stake a set amount of $NES. They put their own tokens at risk before being assigned work.
If a miner returns faulty results or fails to respond, a penalty is deducted from their stake. If they process accurately and quickly, they earn greater rewards.
$NES also serves as a governance tool. Token holders can submit proposals and vote on core network parameters such as fee structures and reward ratios.
In summary, $NES serves three roles: payment for inference requests, collateral and reward for miners, and participation rights in network governance. Without the token, nodes do not run. Without nodes, privacy AI does not function.
One point worth noting: the token economy depends on preconditions to function as designed.
Inference demand must be sufficient for miner rewards to be meaningful. Rewards must be meaningful for miners to stay. Miners must be sufficient for network quality to hold.
This is a virtuous cycle where demand drives supply and supply sustains demand, but getting that cycle started is the hardest phase.
The fact that enterprise clients like Procter & Gamble are already using the network in production is a positive signal. However, whether the balance between token value and mining rewards holds as the network scales remains to be seen.
7. The Case for Privacy AI
The problem Nesa is trying to solve is clear: change the structure in which user data is exposed to third parties whenever AI is used.
The technical foundation is solid. Its core encryption technologies, Equivariant Encryption (EE) and HSS-EE, originated from academic research. The inference optimization scheduler MetaInf was published at the COLM 2025 main conference.
This is not a case of simply citing papers. The research team directly designed the protocols and implemented them in the network.
Among decentralized AI projects, it is rare to find one that has had its own cryptographic primitives validated at the academic level and deployed them onto live infrastructure. The fact that Procter & Gamble and other major enterprises are already running inference on this infrastructure is a meaningful signal for an early-stage project.
That said, limitations are clear.
Market scope: Institutional clients come first; retail users unlikely to pay for privacy yet
Product usability: Playground feels closer to Web3/investment UX than everyday AI tools
Scale validation: Controlled benchmarks ≠ production with thousands of concurrent nodes
Market timing: Demand for privacy AI is real, but demand for decentralized privacy AI is unproven; enterprises still default to centralized APIs
Most enterprises are still accustomed to centralized APIs, and the barrier to adopting blockchain-based infrastructure remains high.
We live in an era where even the head of U.S. cybersecurity uploaded classified documents to AI. Demand for privacy AI already exists and will only grow.
Nesa has academically validated technology and live infrastructure to meet that demand. There are limitations, but its starting position is ahead of other projects.
When the privacy AI market opens in earnest, Nesa will be among the first names that come up.
🐯 More from Tiger Research
Read more reports related to this research.Disclaimer
This report was partially funded by Nesa. It was independently produced by our researchers using credible sources. The findings, recommendations, and opinions are based on information available at publication time and may change without notice. We disclaim liability for any losses from using this report or its contents and do not warrant its accuracy or completeness. The information may differ from others’ views. This report is for informational purposes only and is not legal, business, investment, or tax advice. References to securities or digital assets are for illustration only, not investment advice or offers. This material is not intended for investors.
Terms of Usage
Tiger Research allows the fair use of its reports. ‘Fair use’ is a principle that broadly permits the use of specific content for public interest purposes, as long as it doesn’t harm the commercial value of the material. If the use aligns with the purpose of fair use, the reports can be utilized without prior permission. However, when citing Tiger Research’s reports, it is mandatory to 1) clearly state ‘Tiger Research’ as the source, 2) include the Tiger Research logo following brand guideline. If the material is to be restructured and published, separate negotiations are required. Unauthorized use of the reports may result in legal action.

