

AI technology permeates every aspect of our lives. Growing dependency erodes our control. Sovereign AI has become essential, not optional. Gradient’s challenge demonstrates whether we can achieve true AI independence.
Key Takeaways
Gradient connects idle computing resources worldwide into a distributed network. This challenges the AI industry structure a few Big Tech companies dominate.
The Open Intelligence Stack enables anyone to train and run LLMs without their own infrastructure.
The team includes researchers from UC Berkeley, HKUST, and ETH Zurich. They collaborate with Google DeepMind and Meta to drive continuous advancement.
1. The Dependency Trap: Risks Behind AI Convenience
Anyone can now build prototypes by conversing with LLMs or generate images without design experience.
However, this capability can disappear at any moment. We don’t fully own or control it. A few large companies (OpenAI, Anthropic, and others) provide the foundational infrastructure that most services run on. We depend on their systems.
Consider if these companies revoke LLM access. Server outages could halt services. Companies could block specific regions or users for various reasons. Price increases could push individuals and small businesses out of the market.

When this occurs, “do anything” capability becomes “do nothing” helplessness instantly. Growing dependency amplifies this risk.

This risk already exists. In 2025, Anthropic blocked Claude API access to AI coding startup Windsurf without notice after news of a competitor’s acquisition. The incident restricted model access for some users and forced emergency infrastructure reorganization. One company’s decision immediately impacted another company’s service operations.
This appears to affect only some companies like Windsurf today. As dependency grows, everyone faces this problem.
2. Gradient: Opening the Future with Open Intelligence

Gradient solves this problem. The solution is simple: provide an environment where anyone can develop and run LLMs in a decentralized manner without restrictions, freeing users from control by a few companies like OpenAI or Anthropic.
How does Gradient make this possible? Understanding how LLMs work clarifies this. Training creates LLMs, and inference operates them.
Training: The stage that creates AI models. Models analyze massive datasets to learn patterns and rules, such as which words likely follow others and which answers suit which questions.
Inference: The stage that uses trained models. Models receive user questions and generate the most likely responses based on learned patterns. When you chat with ChatGPT or Claude, you perform inference.
Both stages require massive costs and computing resources.
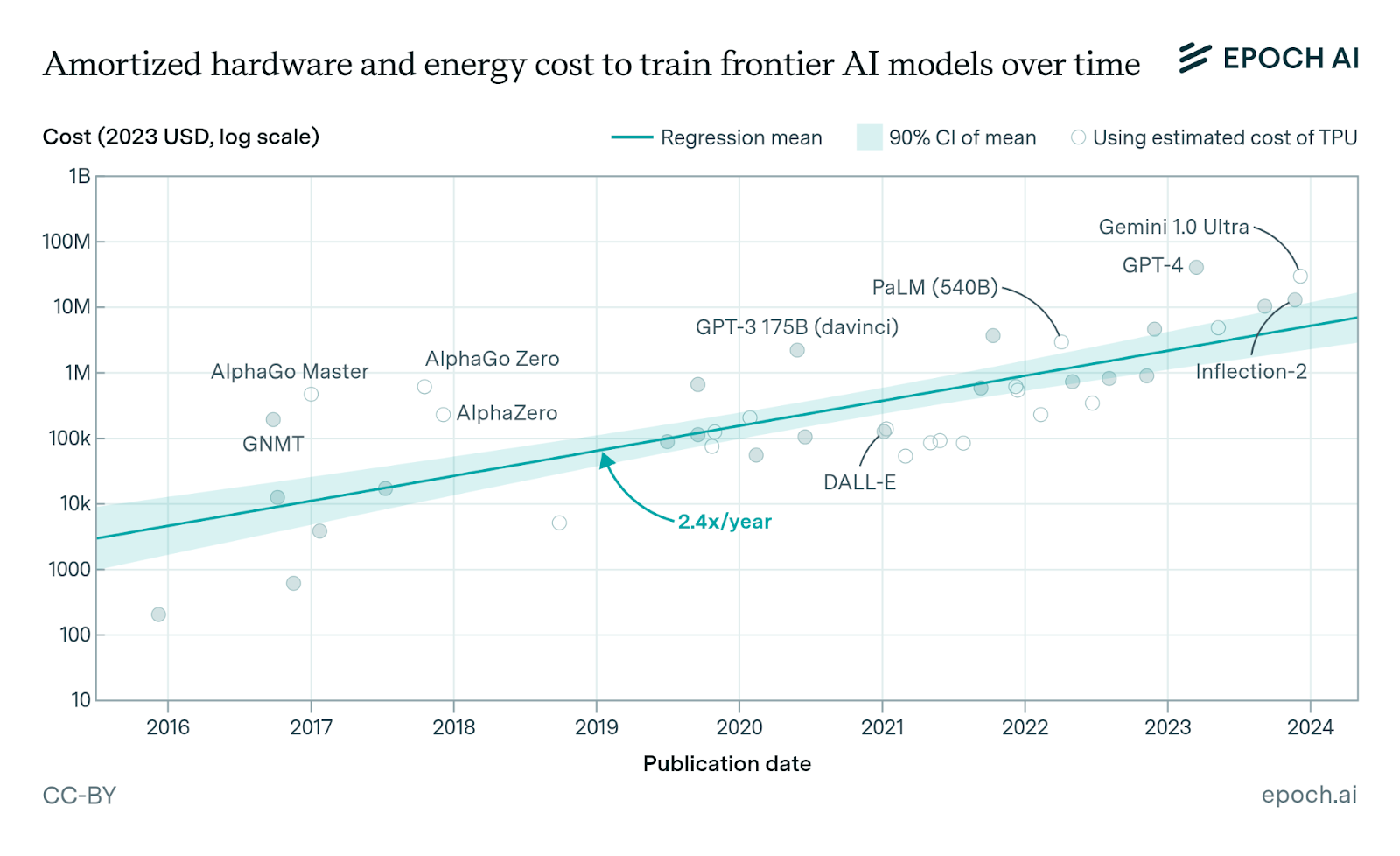
Training GPT-4 alone cost an estimated $40+ million, requiring tens of thousands of GPUs running for months. Inference also demands high-performance GPUs for every response generated. These high cost barriers forced the AI industry to consolidate around capital-rich Big Tech companies.
Gradient solves this differently. While Big Tech builds massive data centers with tens of thousands of high-performance GPUs, Gradient connects idle computing resources worldwide into one distributed network. Home PCs, idle office servers, and lab GPUs operate as one giant cluster.
This enables individuals and small businesses to train and run LLMs without their own infrastructure. Ultimately, Gradient realizes Open Intelligence: AI as technology open to everyone, not the exclusive domain of a few.
3. Three Core Technologies Enabling Open Intelligence
Gradient’s Open Intelligence sounds attractive, but implementing it is complex. Computing resources worldwide vary in performance and specifications. The system must connect and coordinate them reliably.
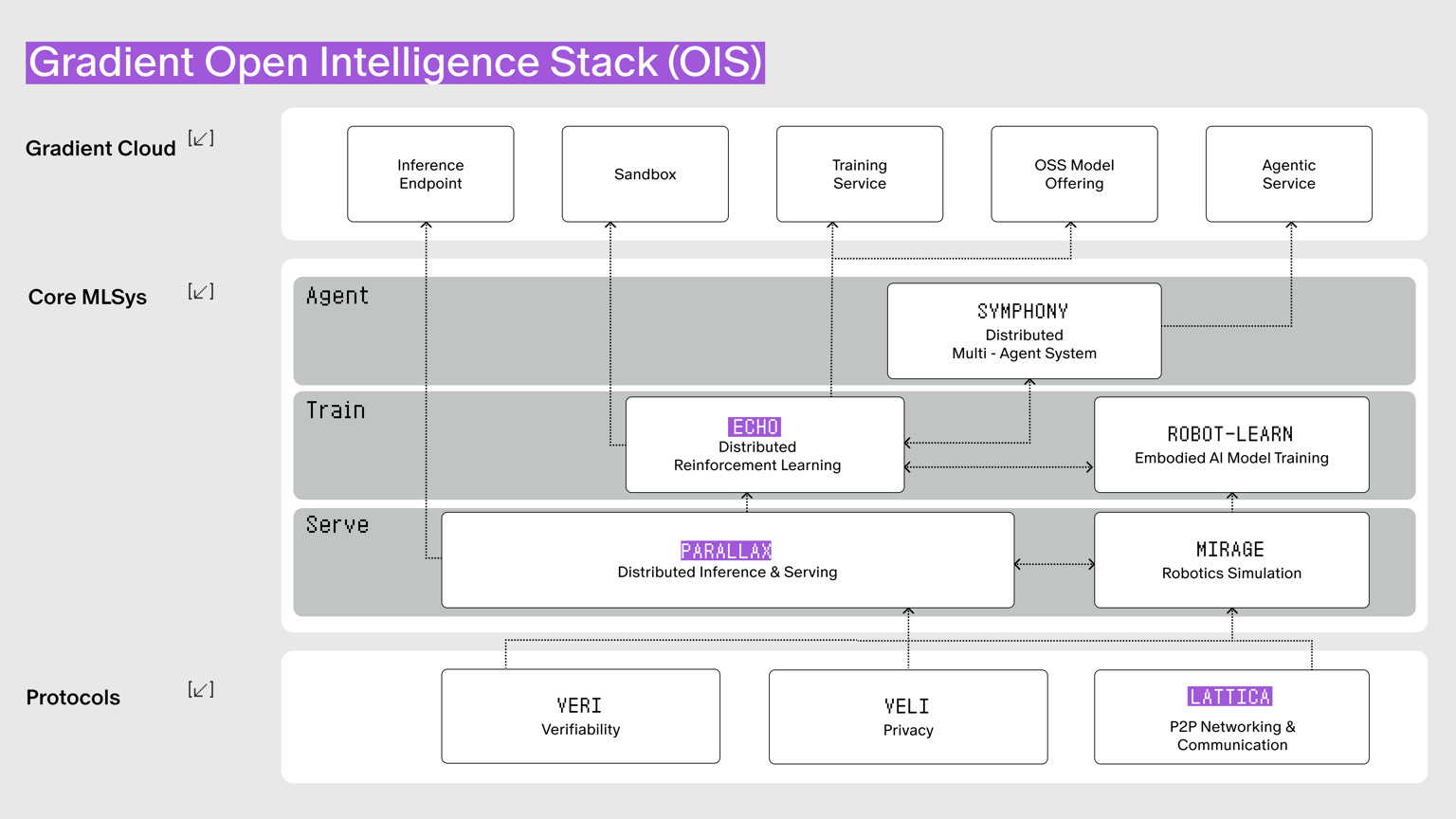
Gradient solves this with three core technologies. Lattica establishes the communication network in distributed environments. Parallax handles inference within this network. Echo trains models through reinforcement learning. These three technologies connect organically to form the Open Intelligence Stack.
3.1. Lattica: P2P Data Communication Protocol
Central servers connect typical internet services. Even when we use messaging apps, central servers relay our communications. Distributed networks operate differently: each computer connects and communicates directly without central servers.
Most computers block direct connections and prevent external access. Routers route home internet connections, preventing external sources from locating individual computers directly. Finding a specific apartment unit with only the building address illustrates this challenge.
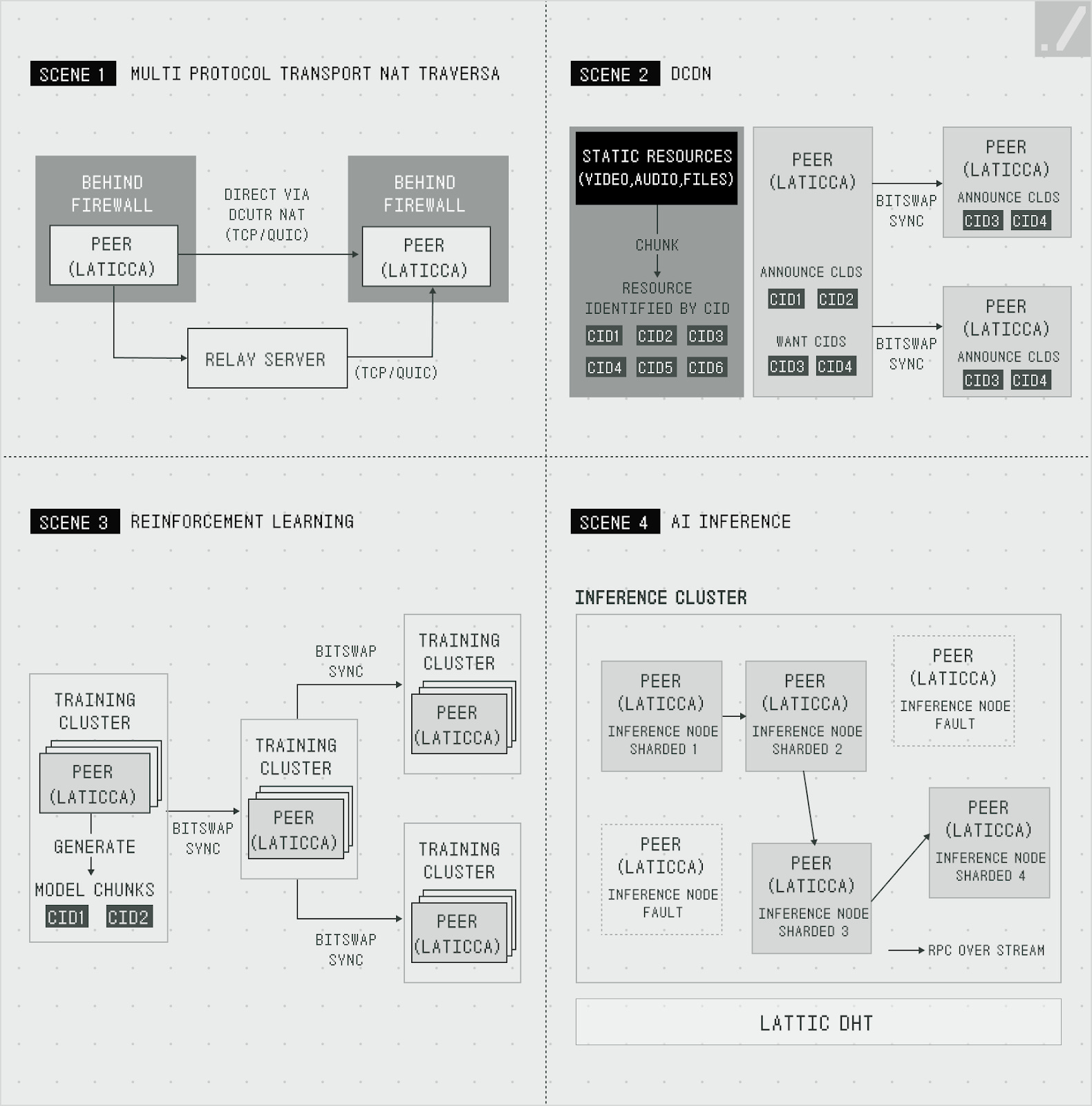
Lattica solves this problem effectively. Hole Punching technology creates temporary “tunnels” through firewalls or NAT (Network Address Translation), enabling direct computer-to-computer connections. This builds P2P networks where computers worldwide connect directly, even in restricted and unpredictable environments. Once connections form, encryption protocols secure communications.
Distributed environments require simultaneous data exchange and rapid synchronization across multiple nodes to run LLMs and deliver results. Lattica uses the BitSwap protocol (similar to torrents) to efficiently transfer model files and intermediate processing results.
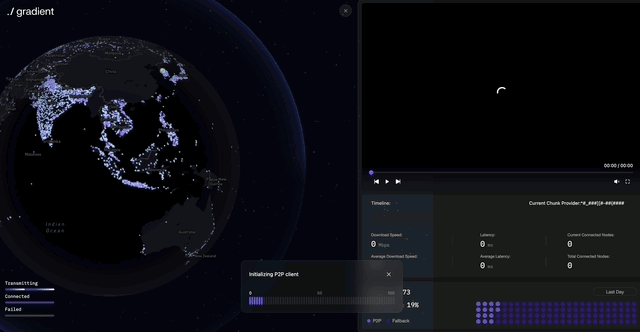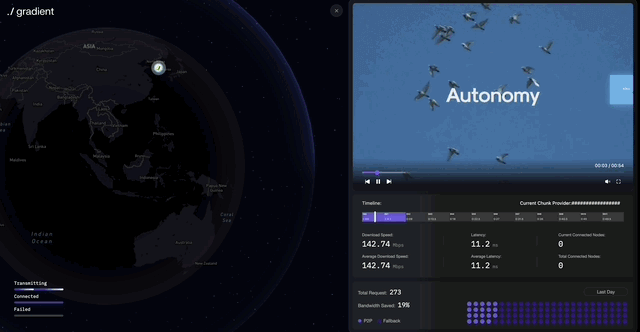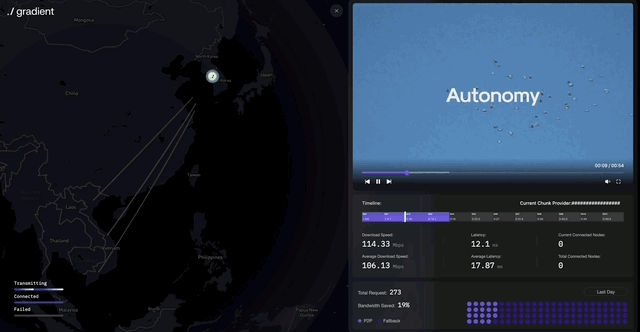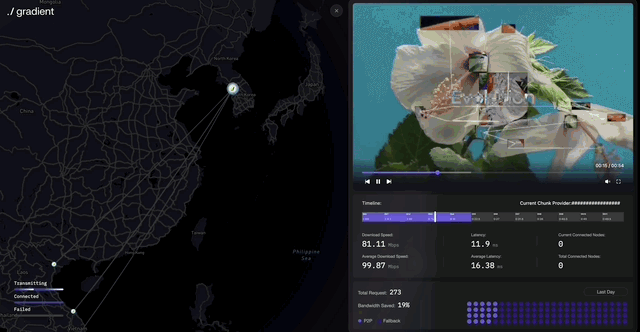
Lattica enables stable and efficient data exchange in distributed environments. The protocol supports AI training and inference, plus applications like distributed video streaming. Lattica’s demo shows how it works.
3.2. Parallax: Distributed Inference Engine
Lattica solved the problem of connecting computers worldwide. Users face one remaining challenge: running LLMs. Open-source models continue advancing, but most users still cannot run them directly. LLMs require massive computing resources. Even DeepSeek’s 60B model demands high-performance GPUs.
Parallax solves this problem. Parallax divides one large model by layers and distributes them across multiple devices. Each device processes its assigned layer and passes results to the next device. Automotive assembly lines work similarly: each stage processes one part to complete the final result.
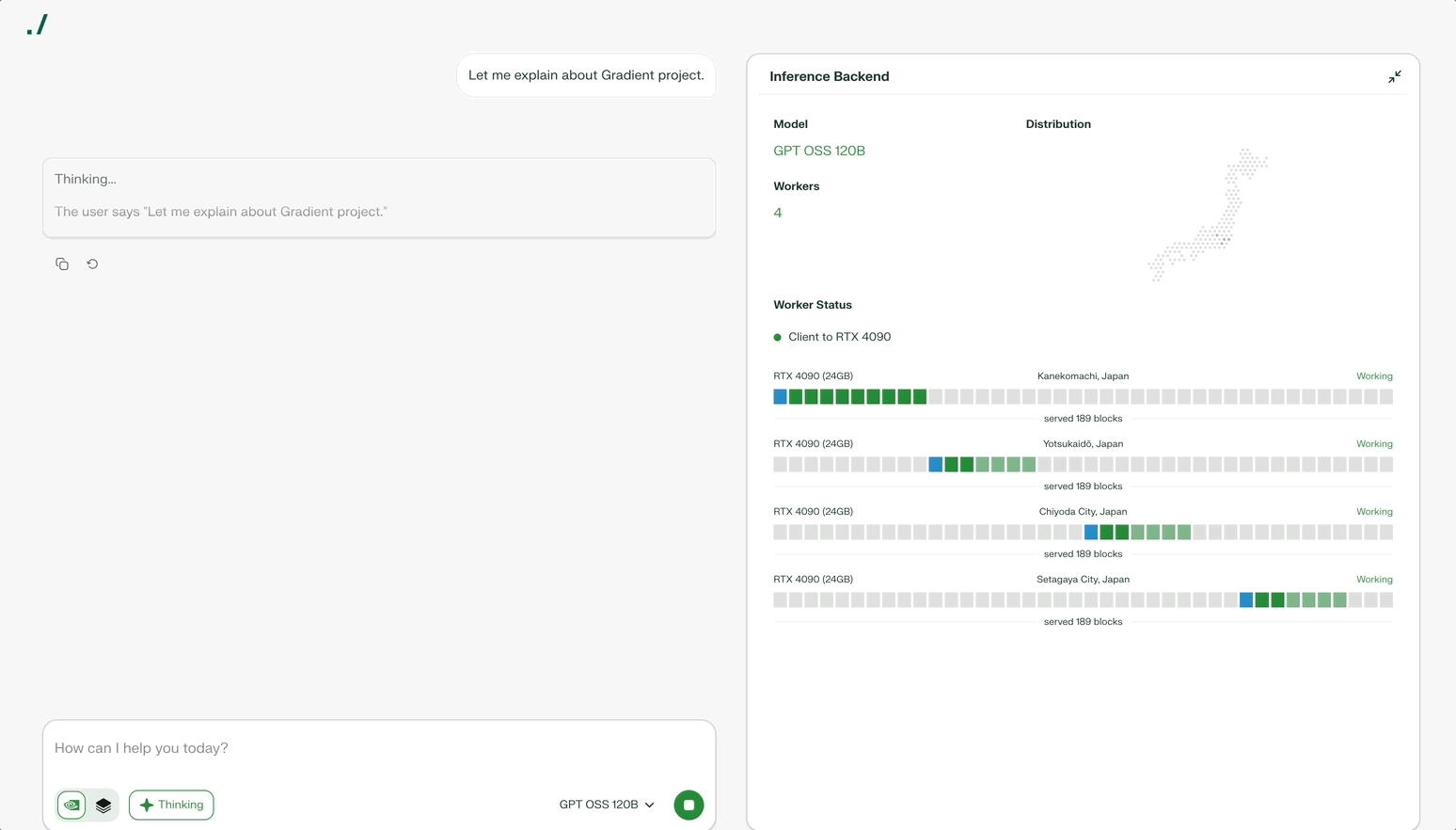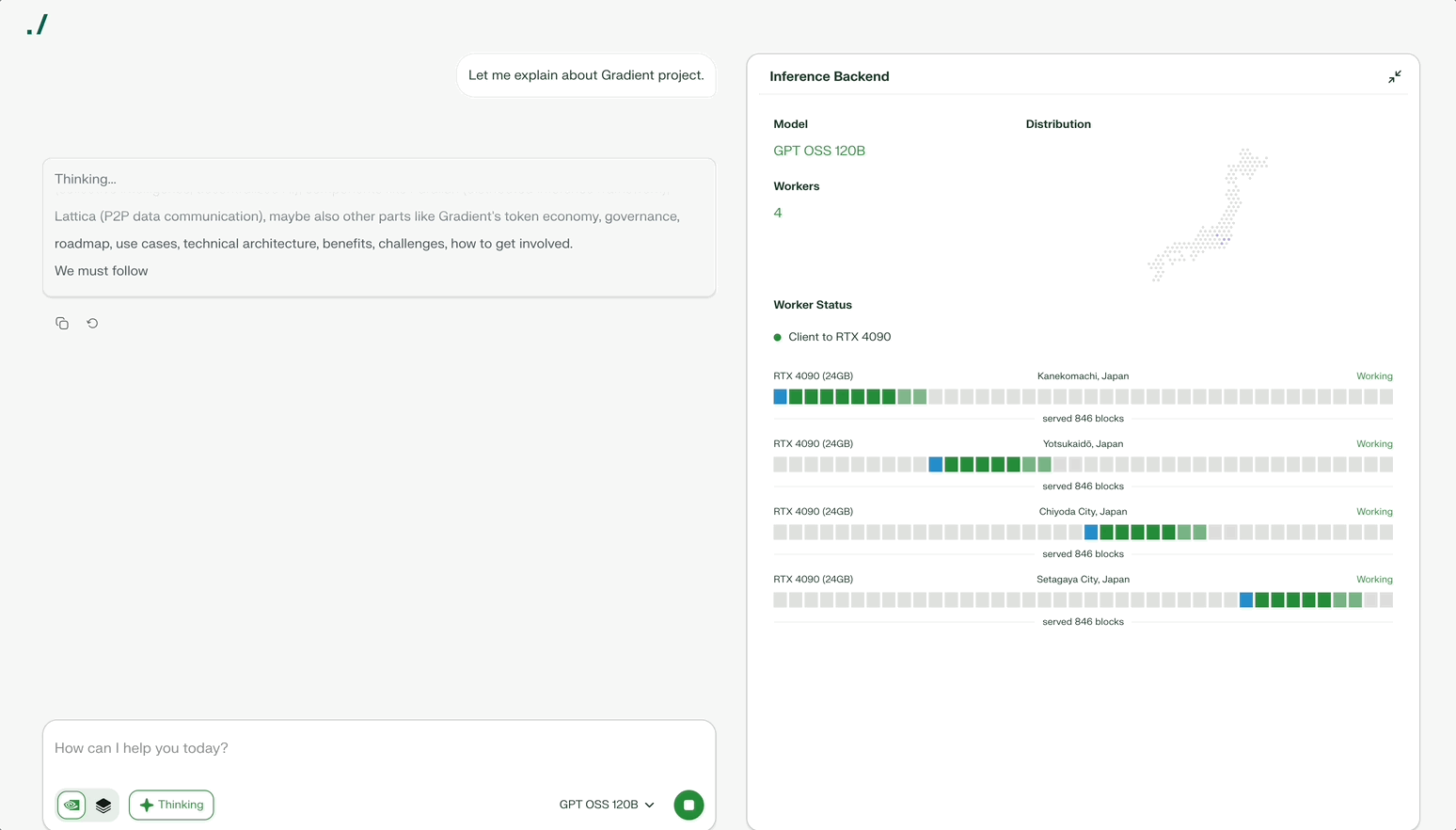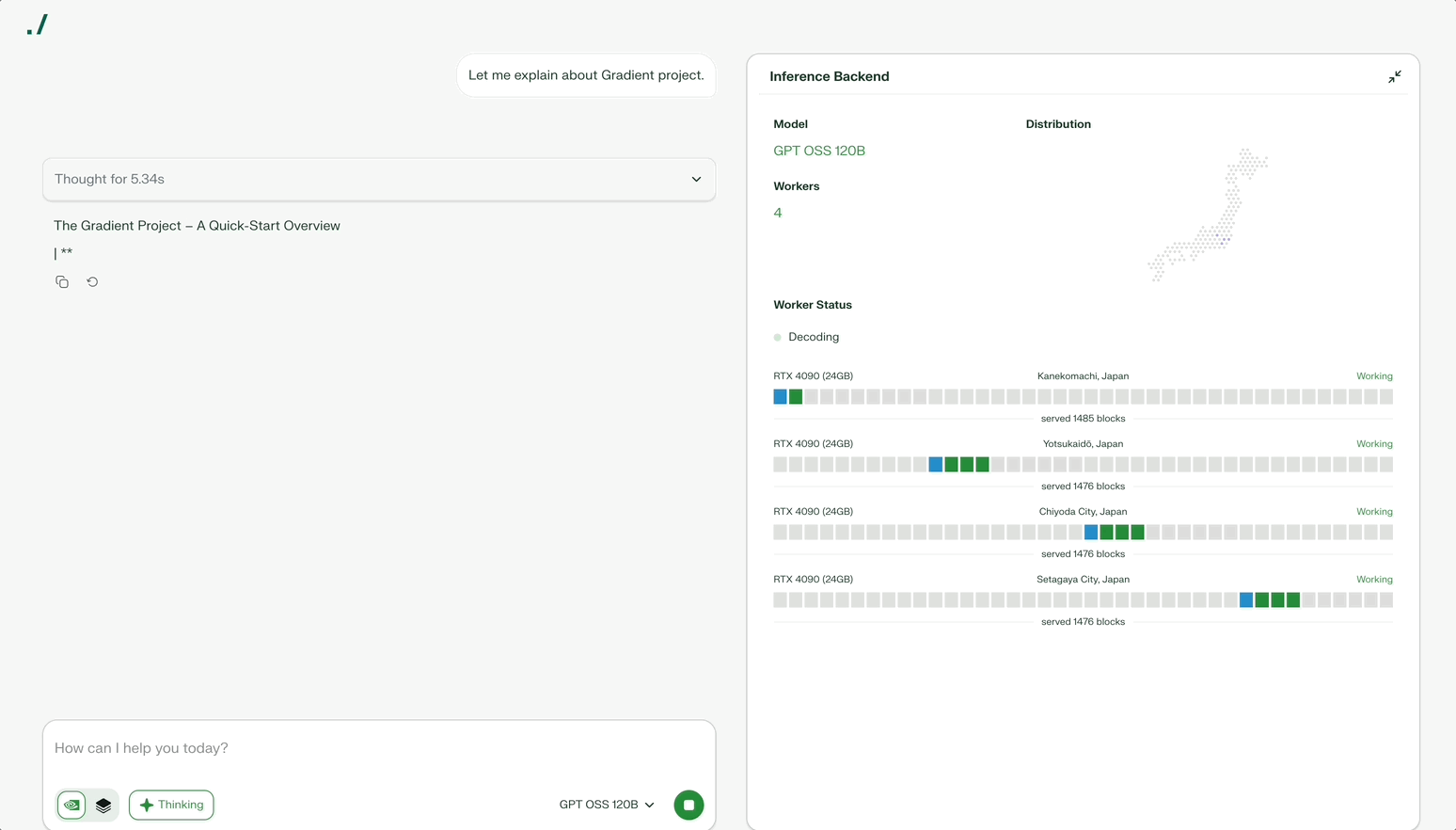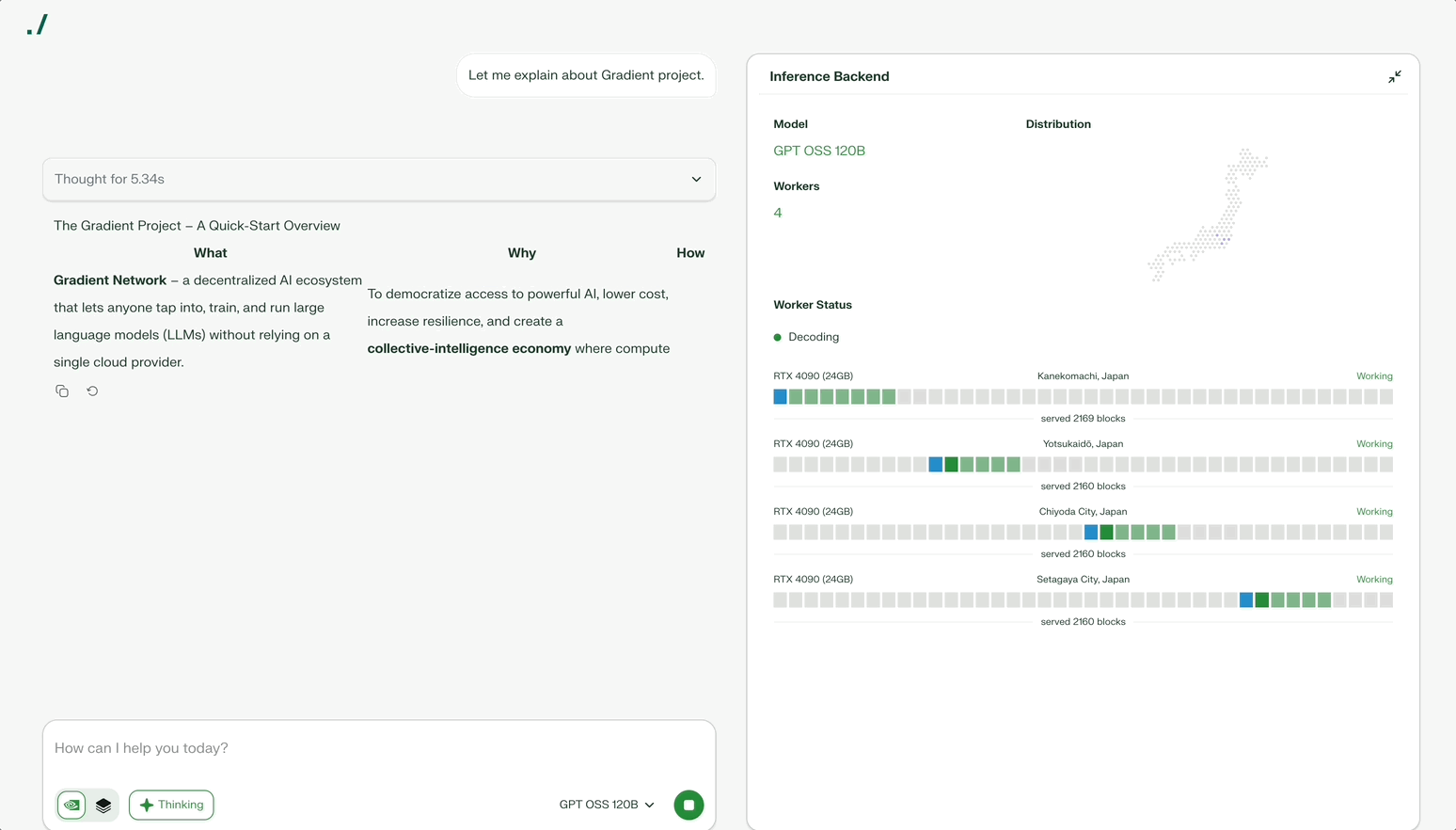
Division alone fails to achieve efficiency. Participating devices vary in performance. When high-performance GPUs process quickly but the next device processes slowly, bottlenecks form. Parallax analyzes each device’s performance and speed in real-time to find optimal combinations. The system minimizes bottlenecks and efficiently utilizes all devices.
Parallax offers flexible options based on needs. The system currently supports over 40 open-source models including Qwen and Kimi. Users select and run their preferred models. Users adjust execution methods based on model size. LocalHost runs small models on personal PCs (like Ollama). Co-Host connects multiple devices within families or teams. Global Host joins the worldwide network.
3.3. Echo: Distributed Reinforcement Learning Framework
Parallax enables anyone to run models. Echo tackles model training. Pre-trained LLMs limit practical applications. AI needs additional training for specific tasks to become truly useful. Reinforcement Learning (RL) provides this training.
Reinforcement learning teaches AI through trial and error. AI repeatedly solves math problems while the system rewards correct answers and penalizes wrong answers. Through this process, AI learns to produce accurate answers. Reinforcement learning enables ChatGPT to respond naturally to human preferences.
LLM reinforcement learning demands massive computing resources. Echo divides the reinforcement learning process into two stages and deploys optimized hardware for each stage.
The inference stage comes first. AI solves math problems 10,000 times and collects data on correct and incorrect answers. Echo prioritizes running many simultaneous attempts over complex calculations.
The training stage follows. Echo analyzes collected data to identify which approaches produced good results. The system then adjusts the model so AI follows those approaches next time. Echo processes complex mathematical operations quickly during this stage.
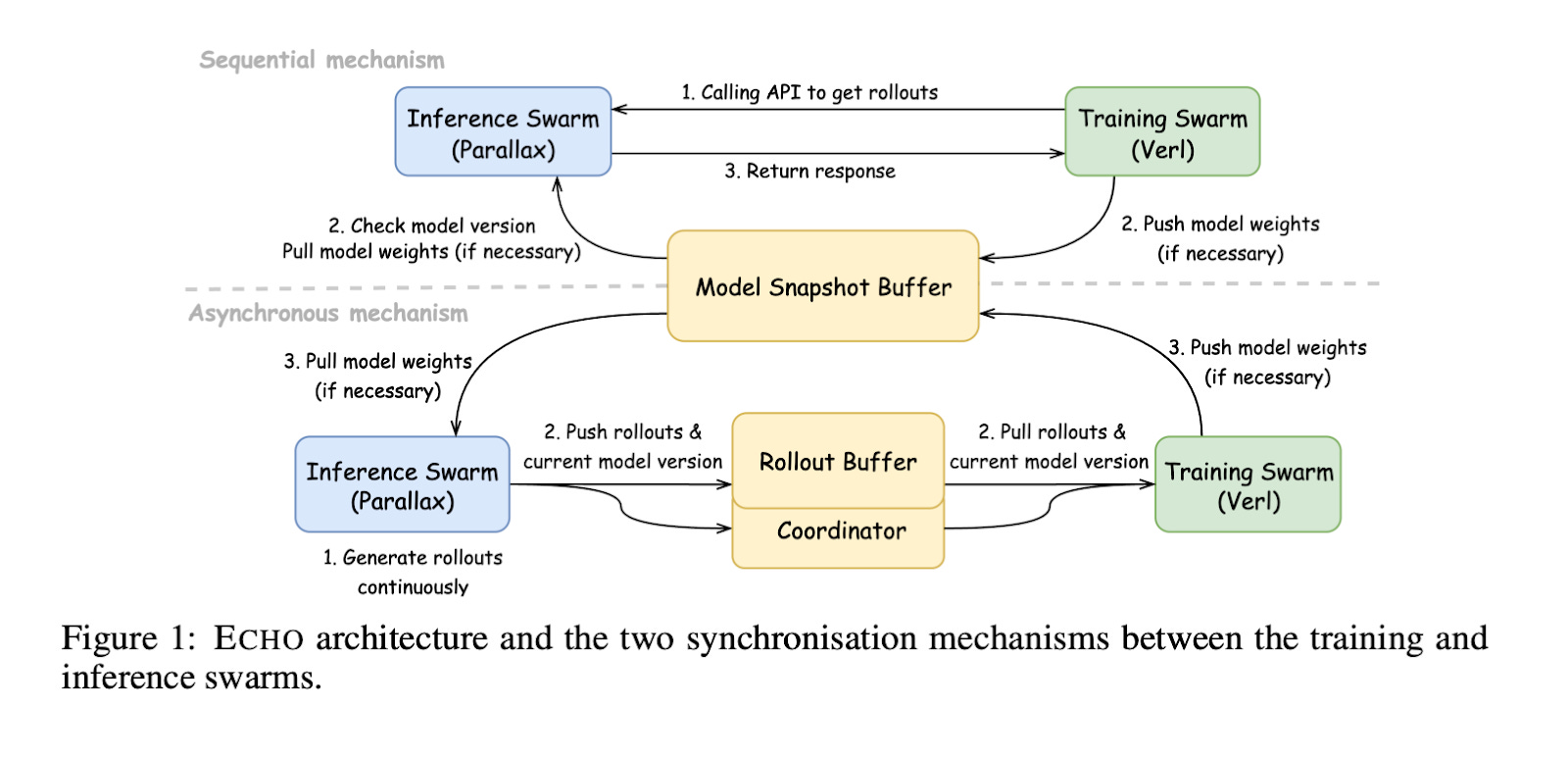
Echo deploys these two stages on separate hardware. The Inference Swarm uses Parallax to operate on consumer PCs worldwide. Multiple consumer devices like RTX 5090 or MacBook M4 Pro simultaneously generate training samples. The Training Swarm uses high-performance GPUs like A100 to rapidly improve models.
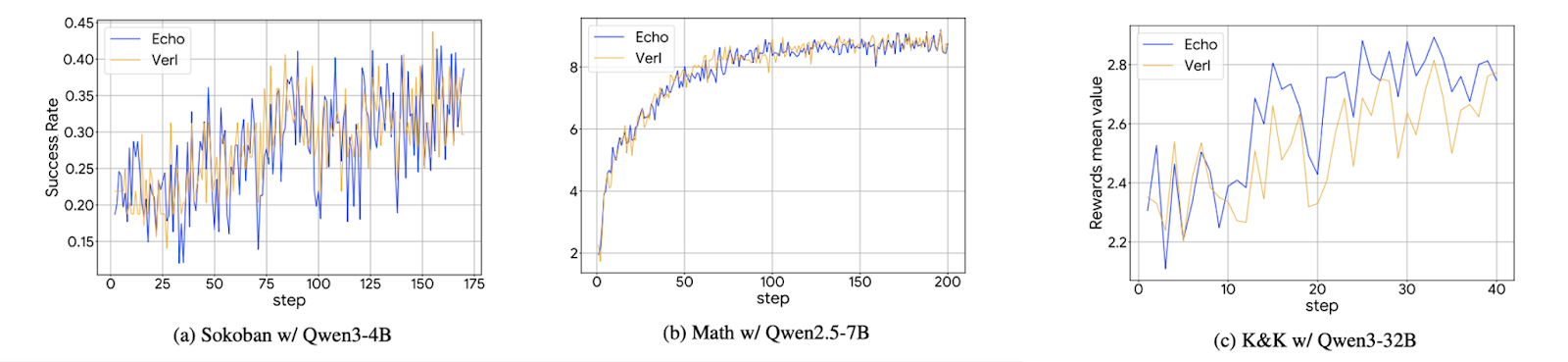
Results prove Echo works. Echo achieves performance equal to VERL, the existing reinforcement learning framework. Individuals and small businesses can now train LLMs for their specific purposes in distributed environments. Echo dramatically lowers the barrier to reinforcement learning.
4. Sovereign AI: New Possibilities Through Open Intelligence
AI has become essential, not optional. Sovereign AI grows increasingly important. Sovereign AI means individuals, companies, and nations own and control AI independently without external dependence.

The Windsurf case demonstrates this clearly. Anthropic blocked Claude API access without notice. The company immediately faced service paralysis. When infrastructure providers block access, companies suffer instant operational damage. Data breach risks compound these problems.
Nations face similar challenges. AI technology advances rapidly around the US and China while other nations grow increasingly dependent. Most LLMs use 90% English in their pre-training data. This language imbalance creates risks that non-English speaking nations will face technical exclusion.
[Ongoing Research Projects]
Veil & Veri: Privacy protection and verification layer for AI (inference verification, training verification)
Mirage: Distributed simulation engine and robot learning platform for physical-world AI
Helix: Self-evolving learning framework for software agents (SRE)
Symphony: Multi-agent self-improvement coordination framework for swarm intelligence
Gradient’s Open Intelligence Stack offers an alternative to this problem. Challenges remain. How does the system verify computation results in distributed networks? How does the system guarantee quality and reliability in an open structure where anyone can participate? Gradient conducts ongoing research and development to solve these challenges.

Researchers from UC Berkeley, HKUST, and ETH Zurich consistently produce results in distributed AI systems. Collaborations with Google DeepMind and Meta accelerate technological advancement. The investment market already recognizes these efforts. Gradient raised $10 million in seed funding co-led by Pantera Capital and Multicoin Capital, with participation from Sequoia China (now HSG).
AI technology will grow more important. Who owns and controls it becomes the critical question. Gradient moves toward Open Intelligence accessible to everyone, not monopolized by a few. The future they envision deserves attention.
🐯 More from Tiger Research
이번 리서치와 관련된 더 많은 자료를 읽어보세요.Disclaimer
This report was partially funded by Gradient. It was independently produced by our researchers using credible sources. The findings, recommendations, and opinions are based on information available at publication time and may change without notice. We disclaim liability for any losses from using this report or its contents and do not warrant its accuracy or completeness. The information may differ from others’ views. This report is for informational purposes only and is not legal, business, investment, or tax advice. References to securities or digital assets are for illustration only, not investment advice or offers. This material is not intended for investors.
Terms of Usage
Tiger Research allows the fair use of its reports. ‘Fair use’ is a principle that broadly permits the use of specific content for public interest purposes, as long as it doesn’t harm the commercial value of the material. If the use aligns with the purpose of fair use, the reports can be utilized without prior permission. However, when citing Tiger Research’s reports, it is mandatory to 1) clearly state ‘Tiger Research’ as the source, 2) include the Tiger Research logo following brand guideline. If the material is to be restructured and published, separate negotiations are required. Unauthorized use of the reports may result in legal action.
