

This report was written by Tiger Research, analyzing Subsquid’s decentralized data infrastructure that bridges the gap between blockchain data transparency and accessibility.
TL;DR
Subsquid (hereafter SQD) simplifies blockchain data access through decentralized infrastructure. It supports over 200 blockchains and distributes data across multiple nodes.
The SQD Network uses a modular structure that allows developers to freely configure data processing and storage methods. This enables users to efficiently utilize data through a unified structure in a multi-chain environment.
Subsquid aims to become the data backbone of Web3, similar to how Snowflake set the standard with “One Platform, Many Workloads.” Through the recent Rezolve AI acquisition, it is expanding into AI and payments. SQD is expected to become core infrastructure connecting Web3 and the agent economy.
1. Is Blockchain Data Really Open to Everyone?
One of blockchain technology’s defining features is that all data is open to everyone. Traditional industries store data in closed databases that are inaccessible from the outside. Blockchain operates differently. All records are transparently published on-chain.
However, transparent data does not guarantee easy utilization. Data transparency does not ensure accessibility. Blockchain is optimized for executing transactions securely and achieving network consensus. It is not infrastructure designed for data analysis. The functions for verifying and storing data have advanced, but the infrastructure for efficiently querying and utilizing that data remains insufficient. The methods for querying on-chain data have not changed significantly from ten years ago to today.

Consider this analogy. A town called “Tiger Town” has a massive river named “Ethereum.” This river is a public good. Anyone can draw water from it. However, drawing water is difficult and inefficient. Each person must go to the riverbank with a bucket and draw water directly. To use it as drinking water, they must boil or filter it through a purification process.
The current blockchain development environment operates this way. Abundant data is readily available, but infrastructure to utilize it is lacking. For example, assume a developer wants to build a dApp using transaction data from Uniswap, a decentralized exchange. The developer must request data through Ethereum’s RPC nodes, process it, and store it. However, RPC nodes have limitations for large-scale data analysis or complex query execution. The blockchain ecosystem operates in a multi-chain environment with multiple blockchains beyond Ethereum. This makes the problem more complex.
Developers can use centralized services like Alchemy or Infura to address these limitations. However, this approach undermines decentralization, a core value of blockchain technology. Even if smart contracts are decentralized, centralized data access creates censorship risks and a single point of failure. The blockchain ecosystem needs a fundamental innovation in data access methods to achieve true accessibility.
2. Subsquid: A New Paradigm for Blockchain Data Infra

Subsquid (hereafter SQD) is a decentralized data infrastructure project designed to address the complexity and inefficiency of blockchain data access. SQD’s goal is to enable anyone to utilize blockchain data easily.
Return to the earlier analogy. In the past, each person had to go to the riverbank with a bucket to draw water directly. Now, distributed water purification plants draw water from the river and purify it. The townspeople no longer need to go to the riverbank. They can receive clean water whenever they need it. The SQD team provides this infrastructure through the “SQD Network.”
The SQD Network operates as a distributed query engine and data lake. It currently supports data from over 200 blockchain networks. Since the mainnet launch in June 2024, it has grown to process hundreds of millions of queries each month. This growth stems from three core features. These features position SQD beyond a simple data indexing platform and demonstrate the evolution direction of blockchain data infrastructure.
2.1. Decentralized Architecture for High Availability
A significant portion of existing blockchain data infrastructure relies on centralized providers like Alchemy. This approach offers advantages in initial accessibility and management efficiency. However, it restricts users to chains supported by the provider and imposes high costs as usage increases. It is also vulnerable to single points of failure. The centralized structure conflicts with blockchain’s core value of decentralization.
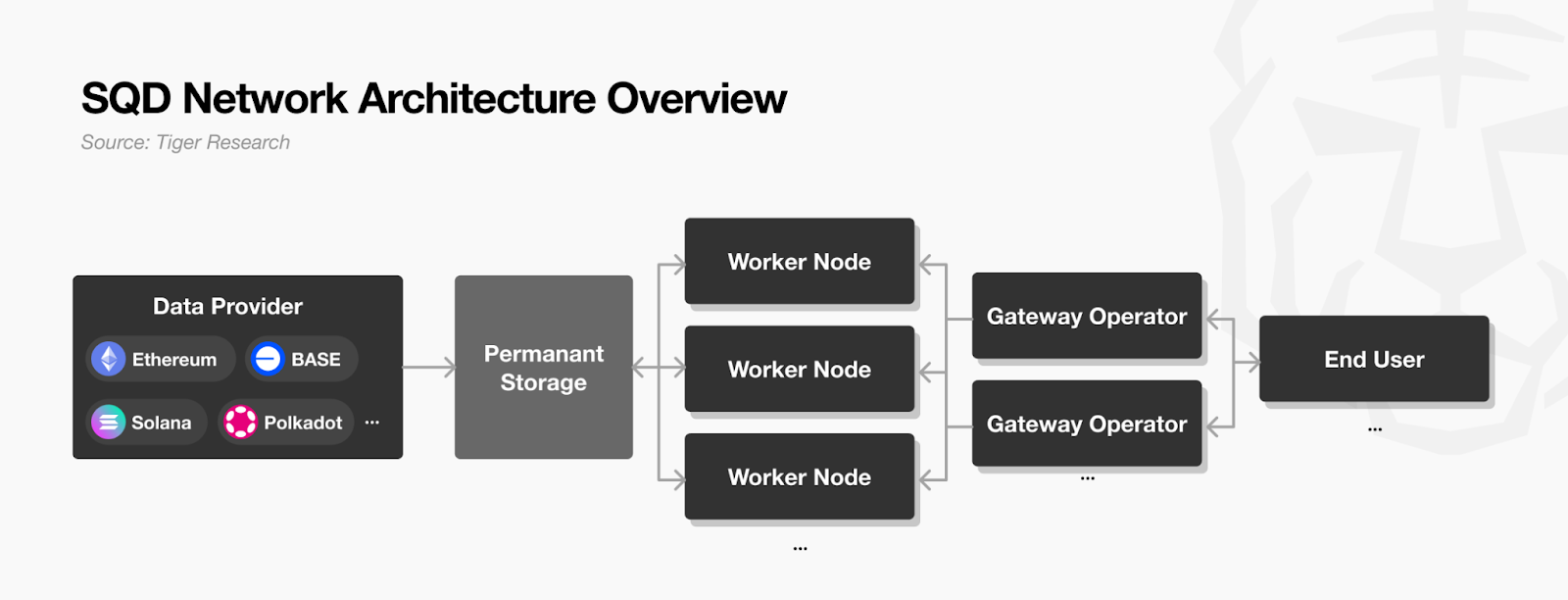
The SQD Network addresses these limitations through a decentralized architecture. Data Providers collect raw data from multiple blockchains such as Ethereum and Solana. They divide the data into blocks, compress it, and upload it to the network with metadata. Worker Nodes split the data from Permanent Storage created by Data Providers into chunks for distributed storage. When query requests arrive, they process and respond quickly. Each Worker Node acts as a mini API that serves its own stored data. The entire network operates like thousands of distributed API servers. Gateway Operators serve as the interface between end users and the network. They receive user queries and forward them to appropriate Worker Nodes for processing.
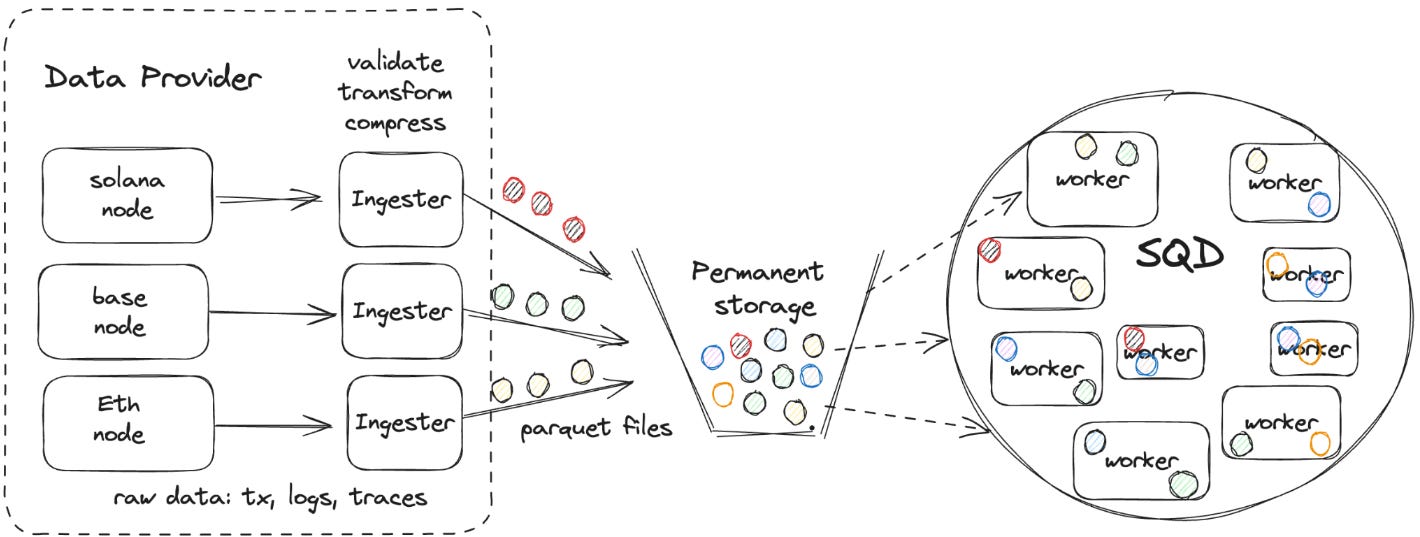
Anyone can participate as a Worker Node or Gateway Operator. This allows the network capacity and processing performance to scale horizontally. Data is redundantly stored across multiple Worker Nodes. If some nodes fail, overall data access remains unaffected. This ensures high availability and resilience.
Data Providers are currently managed by the SQD team during the initial bootstrap phase. This strategy ensures initial data quality and stability. As the network matures, external providers will be able to participate through token governance. This will fully decentralize the data sourcing stage.
2.2. Tokenomics for Network Sustainability
For a distributed network to function properly, participants need motivation to act voluntarily. SQD addresses this through an economic incentive structure centered on the native token $SQD. Each participant stakes or delegates tokens according to their role and responsibility. This builds network stability and reliability collectively.
Worker Nodes are the core operators that manage blockchain data. To participate, they must stake 100,000 $SQD as collateral against malicious behavior or incorrect data provision. If problems occur, the network slashes their deposits. Nodes that consistently provide stable and accurate data receive $SQD token rewards. This naturally incentivizes responsible operation.
Gateway Operators must lock up $SQD tokens to process user requests. The amount of locked tokens determines their bandwidth, or the number of requests they can handle. Longer lockup periods allow them to process more requests.
Token holders can participate in the network indirectly without running nodes themselves. They can delegate their stake to trusted Worker Nodes. Nodes that receive more delegations gain authority to process more queries and earn more rewards. Delegators share a portion of these rewards. Currently, there are no minimum delegation requirements or lockup period restrictions. This creates a permissionless curation system where the community selects nodes in real-time. The entire community participates in network quality management through this structure.
2.3. Modular Structure for Flexibility
Another distinctive feature of the SQD Network is its modular structure. Existing indexing solutions adopt a monolithic structure that processes everything from data collection to processing, storage, and querying in a single system. This simplifies initial setup but limits developers’ freedom to choose data processing methods or storage locations.
SQD completely separates the data access layer from the processing layer. The SQD Network handles only the E (Extract) portion of the ETL (Extract-Transform-Load) pipeline. It serves solely as a “data feed” that extracts blockchain raw data quickly and reliably. Developers use the SQD SDK to freely choose how to transform and store the data.
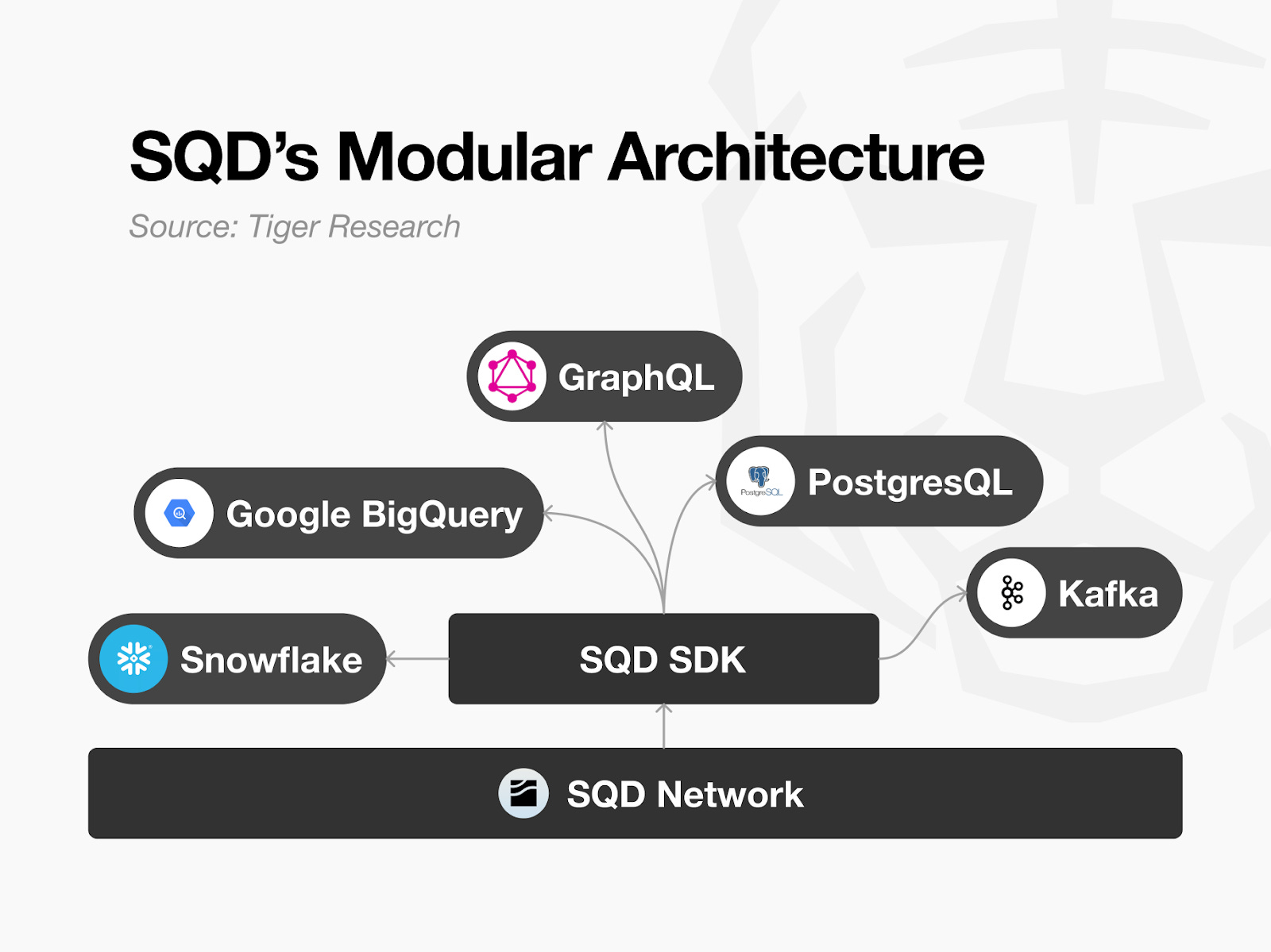
This structure provides practical flexibility. Developers can store data in PostgreSQL and serve it through a GraphQL API. They can export it as CSV or Parquet files. They can load it directly into cloud data warehouses like Google BigQuery. Future plans include supporting large-scale data analysis environments through Snowflake and enabling real-time analysis and monitoring platforms by streaming data directly through Kafka integration without separate storage.
SQD co-founder Dmitry Zhelezov compares this to “providing Lego blocks.” Instead of offering a finished product, SQD hands developers the highest-performing and most reliable raw materials. Developers combine these materials according to their requirements to complete their own data infrastructure. Traditional enterprises and crypto projects alike can handle blockchain data using familiar tools and languages. They can flexibly build data pipelines optimized for their specific industries and use cases.
3. Subsquid’s Next Steps: Toward Better Data Infra
The SQD team has reduced the complexity and inefficiency of blockchain data access through the SQD Network and established the foundation for decentralized data infrastructure. However, as the scale and scope of blockchain data usage expand rapidly, simple accessibility no longer suffices. The ecosystem now demands faster processing speeds and more flexible utilization environments.
The SQD team is advancing the network structure to meet these demands. The team focuses on increasing data processing speed and creating a structure that enables data handling without server dependence. To achieve this, SQD is developing 1) SQD Portal and 2) Light Squid in stages.
3.1. SQD Portal: Decentralized Parallel Processing and Real-Time Data
In the existing SQD Network, the Gateway served as an intermediary connecting end users and Worker Nodes. When users requested queries, the Gateway forwarded them to appropriate Worker Nodes and returned responses to end users. This process was stable but processed queries sequentially one at a time. Large-scale queries took considerable time. Even with thousands of Worker Nodes available, the system underutilized their processing capacity.
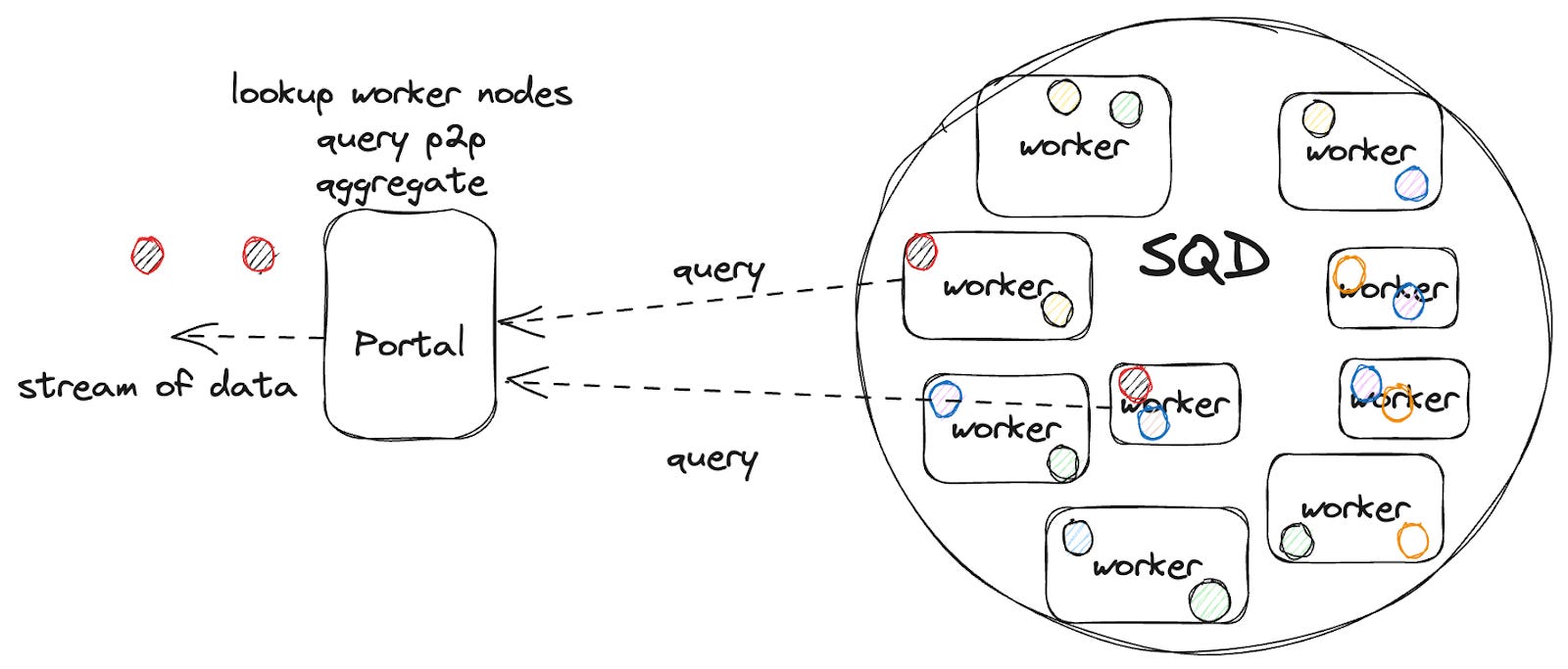
The SQD team aims to solve this problem through SQD Portal. The core of Portal lies in decentralized parallel processing. It splits a single query into multiple pieces and sends requests simultaneously to approximately 3,000 or more Worker Nodes. Each Worker Node processes its assigned portion in parallel. Portal then collects these responses in real-time and delivers them through streaming.
Portal prefetches data into buffers in advance. This ensures uninterrupted delivery even when network delays or temporary failures occur. Just as YouTube buffers videos for seamless playback, users receive data without waiting. The team also refactored the existing Python-based query engine to Rust. This dramatically improved parallel processing performance. Overall processing speed increased dozens of times compared to before.
Portal goes further to solve the real-time data problem. No matter how fast data processing becomes, Worker Nodes only hold finalized historical blocks. They cannot retrieve the latest transactions or block information just generated. Users still had to rely on external RPC nodes for this. Portal solves this with real-time distributed streaming called “Hotblocks.” Hotblocks collects newly generated unconfirmed blocks in real-time from blockchain RPC nodes or dedicated streaming services and stores them inside Portal. Portal merges the finalized historical data from Worker Nodes with the latest block data from Hotblocks. Users can receive data from past to present in one request without separate RPC connections.
The SQD team plans to fully transition existing Gateways to Portal. Portal currently operates in closed beta. In the future, anyone will be able to operate Portal nodes directly and perform the Gateway role in the network. Existing Gateway operators will naturally transition to Portal operators. (The SQD Network architecture can be found at this link.)
3.2. Light Squid: Indexing in Local Environments
The SQD Network provides data reliably, but developers still face the limitation of operating separate servers. Even when retrieving data from Worker Nodes through Portal, large database servers like PostgreSQL were needed to process and deliver it to users. This process requires significant infrastructure construction and maintenance costs. The data still depends on a single provider (developer server), which distances it from a truly distributed structure.
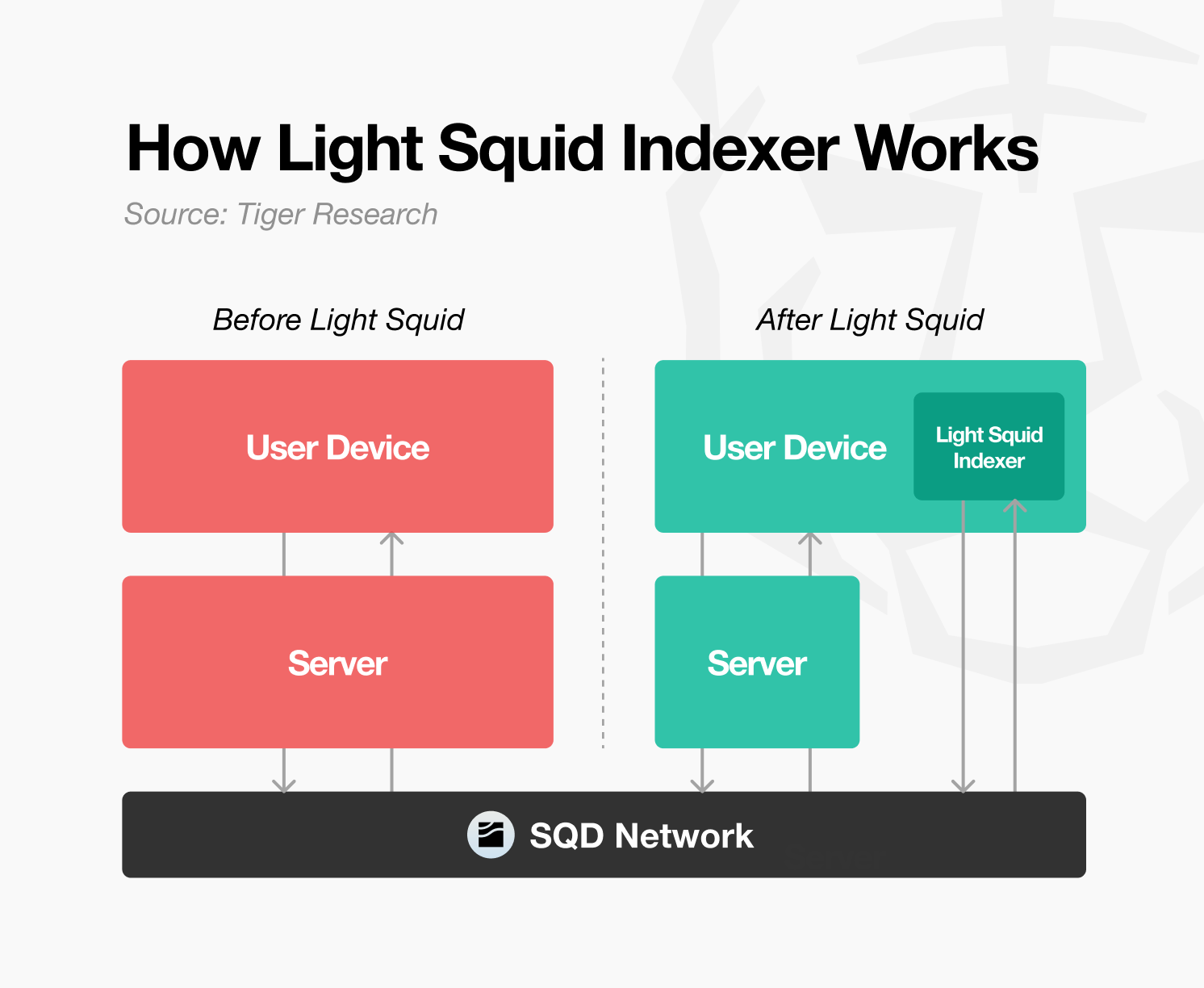
Light Squid simplifies this intermediate step. The existing structure operated like wholesalers (developers) running large warehouses (servers) to distribute data to consumers. Light Squid transforms this into a D2C (Direct to Customer) approach that delivers data directly from the source (SQD Network) to end users. Users receive necessary data through Portal and store it in their local environment. They can query it directly in browsers or personal devices. Developers do not need to maintain separate servers. Users can check locally stored data even when network connections are lost.
For example, an application displaying NFT transaction history can now run directly in a user’s browser without a central server. This mirrors how Instagram shows feeds offline in Web2. It aims to provide dApps with a smooth user experience in local environments. However, Light Squid is designed as an option to enable the same indexing environment locally. It does not completely replace server-centric structures. Data is still supplied through a distributed network. As the scope of utilization extends to the user level, the SQD ecosystem is expected to evolve into a more accessible form.
4. How Subsquid Works in Practice
The SQD Network is simply an infrastructure that provides data, but its scope of application is limitless. Just as all IT-based industries start with data, improvements in data infrastructure expand the possibilities of all services built on top of it. SQD is already changing how blockchain data is utilized across various fields and delivering concrete results.
4.1. DApp Developers: Unified Multi-Chain Data Management
PancakeSwap, a decentralized exchange (DEX), is a representative case. In a multi-chain environment, exchanges must aggregate trading volume, liquidity pool data, and token pair information from each chain in real-time. In the past, developers had to connect to RPC nodes for each chain, parse event logs, and align different data structures individually. This process repeated with every new chain addition. Maintenance burden increased with each protocol upgrade.
After adopting SQD, PancakeSwap can now manage data from multiple chains through a unified pipeline. SQD provides data from each chain in standardized format. A single indexer can now process all chains simultaneously. Chain additions now require only configuration changes. Data processing logic is managed consistently from a central location. The development team reduced time spent on data infrastructure management. They can now focus more on core service improvements.
4.2. Data Analysts: Flexible Data Processing and Integrated Analysis
On-chain analysis platforms like Dune and Artemis provide high accessibility and convenience by allowing quick and easy data queries using SQL. However, they have limitations in that work is only possible within the chains and data structures the platform supports. Additional processes are needed when combining external data or performing complex transformations.
SQD complements this environment and enables data analysts to handle data more freely. Users can directly extract necessary blockchain data, transform it into desired formats, and load it into their own databases or warehouses. For example, analysts can retrieve transaction data from a specific decentralized exchange, aggregate it by time period, combine it with existing financial data, and apply it to their own analysis models. SQD does not replace the convenience of existing platforms. It increases the freedom and scalability of data handling. Analysts can expand the depth and application scope of on-chain data analysis through broader data ranges and customized processing methods.
4.3. AI Agents: Core Infrastructure for Agent Economy
For AI agents to make autonomous decisions and execute transactions, they need infrastructure that guarantees reliability and transparency. Blockchain provides a suitable foundation for autonomous agents. All transaction records are transparently disclosed and difficult to tamper with. Cryptocurrency payments enable automatic execution.
However, AI agents currently struggle to access blockchain infrastructure directly. Each developer must individually build and integrate data sources. Network structures vary and prevent standardized access. Even centralized API services require multiple steps including account registration, key issuance, and payment setup. These processes presume human intervention and do not suit autonomous environments.
The SQD Network bridges this gap. Based on a permissionless architecture, agents automate data requests and payments through $SQD tokens. They receive necessary information in real-time and process it independently. This establishes the operational foundation for autonomous AI that connects directly to data networks without human intervention.

On October 9, 2025, Rezolve AI announced the acquisition of SQD, clarifying this direction further. Rezolve is a NASDAQ-listed AI-based commerce solution provider. Through this acquisition, Rezolve is building core infrastructure for the AI agent economy. Rezolve plans to combine the digital asset payment infrastructure of previously acquired Smartpay with SQD’s distributed data layer. This will create integrated infrastructure where AI processes data, intelligence, and payments in a single flow. Once Rezolve completes this integration, AI agents will analyze blockchain data in real-time and execute transactions independently. This marks a significant turning point for SQD as data infrastructure for the AI agent economy.
4.4. Institutional Investors: Real-Time Data Infra for Institutional Markets
As real-world asset tokenization (RWA) expands, institutional investors are actively participating on-chain. Institutions need data infrastructure that guarantees accuracy and transparency to utilize on-chain data for trading, settlement, and risk management.

SQD launched OceanStream to meet this demand. OceanStream is a decentralized data lakehouse platform that streams data from over 200 blockchains in real-time. The platform aims to provide institution-grade data quality and stability. It combines sub-second latency streaming with over 3PB of indexed historical data to improve financial institutions’ backtesting, market analysis, and risk assessment environments. This allows institutions to monitor more chains and asset classes in real-time at lower costs. They can perform regulatory reporting and market surveillance within a single integrated system.
OceanStream participated in the SEC-hosted Crypto Task Force Roundtable to discuss how transparency and verifiability of on-chain data impact market stability and investor protection. This demonstrates that SQD is establishing itself as a data-based structure connecting tokenized financial markets with institutional capital beyond simple development infrastructure.
5. SQD’s Vision: Building the Data Backbone of Web3
The competitiveness of the Web3 industry depends on how well it utilizes data. However, data remains fragmented due to different blockchain structures. Infrastructure to handle this efficiently is still in its early stages. SQD bridges this gap by building a standardized data layer that handles all blockchain data within a single structure. Beyond on-chain data, SQD plans to integrate off-chain data including financial transactions, social media, and corporate operations to create an analysis environment spanning both worlds.
This vision resembles how Snowflake established the data integration standard for traditional industries with “One Platform, Many Workloads.” SQD aims to establish itself as the data backbone of Web3 by integrating blockchain data and connecting off-chain sources.
However, SQD needs time to develop into a fully decentralized infrastructure. The project is currently in the bootstrap phase where the SQD team still plays a significant role. Limitations exist in developer community size and ecosystem diversity. Nevertheless, the growth shown in just over a year since mainnet launch and the strategic expansion through the Rezolve AI acquisition demonstrate clear direction. SQD is presenting the path forward for blockchain data infrastructure and evolving into a data foundation supporting the entire Web3 ecosystem—from dApp development to institutional investment and the AI agent economy. Its potential is expected to grow significantly.
🐯 More from Tiger Research
Read more reports related to this research.Disclaimer
This report was partially funded by SQD. It was independently produced by our researchers using credible sources. The findings, recommendations, and opinions are based on information available at publication time and may change without notice. We disclaim liability for any losses from using this report or its contents and do not warrant its accuracy or completeness. The information may differ from others’ views. This report is for informational purposes only and is not legal, business, investment, or tax advice. References to securities or digital assets are for illustration only, not investment advice or offers. This material is not intended for investors.
Terms of Usage
Tiger Research allows the fair use of its reports. ‘Fair use’ is a principle that broadly permits the use of specific content for public interest purposes, as long as it doesn’t harm the commercial value of the material. If the use aligns with the purpose of fair use, the reports can be utilized without prior permission. However, when citing Tiger Research’s reports, it is mandatory to 1) clearly state ‘Tiger Research’ as the source, 2) include the Tiger Research logo following brand guideline. If the material is to be restructured and published, separate negotiations are required. Unauthorized use of the reports may result in legal action.

